Tabla de contenidos
Utilice tuberías de Linux para coreografiar cómo colaboran las utilidades de la línea de comandos. Simplifique procesos complejos y aumente su productividad aprovechando una colección de comandos independientes y convirtiéndolos en un equipo con un solo propósito. Te mostramos cómo.
Las tuberías están en todas partes
Las canalizaciones son una de las características de línea de comandos más útiles que tienen los sistemas operativos Linux y tipo Unix. Las tuberías se utilizan de innumerables formas. Mire cualquier artículo de línea de comandos de Linux, en cualquier sitio web, no solo en el nuestro, y verá que las tuberías aparecen la mayoría de las veces. Revisé algunos de los artículos de Linux de How-To Geek, y en todos ellos se utilizan tuberías, de una forma u otra.
Las canalizaciones de Linux le permiten realizar acciones que el shell no admite de forma inmediata . Pero debido a que la filosofía de diseño de Linux es tener muchas utilidades pequeñas que realicen muy bien su función dedicada , y sin una funcionalidad innecesaria, el mantra «haz una cosa y hazlo bien», puedes conectar cadenas de comandos junto con tuberías para que la salida de un comando se convierte en la entrada de otro. Cada comando que ingresa aporta su talento único al equipo, y pronto descubrirá que ha reunido un escuadrón ganador.
Un ejemplo simple
Supongamos que tenemos un directorio lleno de muchos tipos diferentes de archivos. Queremos saber cuántos archivos de cierto tipo hay en ese directorio. Hay otras formas de hacer esto, pero el objeto de este ejercicio es introducir tuberías, así que lo haremos con tuberías.
Podemos obtener una lista de los archivos fácilmente usando ls:
ls

Para separar el tipo de archivo de interés, usaremos grep. Queremos encontrar archivos que tengan la palabra «página» en su nombre de archivo o extensión de archivo.
Usaremos el carácter especial de shell “ |” para canalizar la salida desde lsadentro grep.
ls | grep "página"

grepimprime líneas que coinciden con su patrón de búsqueda . Así que esto nos da una lista que contiene solo archivos «.page».

Incluso este ejemplo trivial muestra la funcionalidad de las tuberías. La salida de lsno se envió a la ventana del terminal. Se envió grepcomo datos para que el grepcomando funcione. La salida que vemos proviene de grep, cuál es el último comando de esta cadena.
Ampliando nuestra cadena
Comencemos a extender nuestra cadena de comandos canalizados. Podemos contar los archivos «.page» agregando el wccomando. Usaremos la -lopción (recuento de líneas) con wc. Tenga en cuenta que también hemos agregado la -lopción (formato largo) a ls. Usaremos esto en breve.
ls - | grep "página" | wc -l

grepya no es el último comando de la cadena, por lo que no vemos su salida. La salida de grepse alimenta al wccomando. La salida que vemos en la ventana del terminal es de wc. wcinforma que hay 69 archivos “.page” en el directorio.
Extendamos las cosas de nuevo. Quitaremos el wccomando de la línea de comandos y lo reemplazaremos con awk. Hay nueve columnas en la salida lscon la -lopción (formato largo). Usaremos awkpara imprimir las columnas cinco, tres y nueve. Estos son el tamaño, el propietario y el nombre del archivo.
ls -l | grep "página" | awk '{print $ 5 "" $ 3 "" $ 9}'
Obtenemos una lista de esas columnas, para cada uno de los archivos coincidentes.
Ahora pasaremos esa salida a través del sortcomando. Usaremos la -nopción (numérica) para sortindicar que la primera columna debe tratarse como números .
ls -l | grep "página" | awk '{imprimir $ 5 "" $ 3 "" $ 9}' | sort -n
La salida ahora está ordenada por tamaño de archivo, con nuestra selección personalizada de tres columnas.
Agregar otro comando
Terminaremos agregando el tailcomando. Le diremos que enumere las últimas cinco líneas de salida solamente.
ls -l | grep "página" | awk '{imprimir $ 5 "" $ 3 "" $ 9}' | sort -n | cola -5
Esto significa que nuestro comando se traduce en algo como «muéstrame los cinco archivos» .page «más grandes de este directorio, ordenados por tamaño». Por supuesto, no hay ningún comando para lograr eso, pero al usar tuberías, hemos creado las nuestras. Podríamos agregar esto, o cualquier otro comando largo, como un alias o función de shell para guardar toda la escritura.
Aquí está el resultado:
Podríamos invertir el orden de tamaño agregando la -ropción (reverse) al sortcomando, y usando en headlugar de tail para seleccionar las líneas de la parte superior de la salida .

Esta vez, los cinco archivos «.page» más grandes se enumeran de mayor a menor:
Algunos ejemplos recientes
Aquí hay dos ejemplos interesantes de artículos recientes de How-To geek.
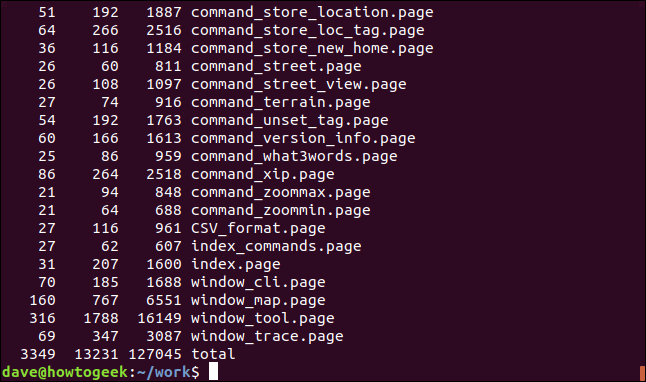
Algunos comandos, como el xargscomando , están diseñados para recibir entradas . Aquí hay una forma en que podemos wc contar las palabras, caracteres y líneas en varios archivos, mediante una canalización lsen la xargsque luego se alimenta la lista de nombres de archivo wccomo si se hubieran pasado wccomo parámetros de línea de comando.
ls * .page | xargs wc
El número total de palabras, caracteres y líneas se enumeran en la parte inferior de la ventana del terminal.
Esta es una forma de obtener una lista ordenada de las extensiones de archivo únicas en el directorio actual, con un recuento de cada tipo.
ls | rev | cortar -d '.' -f1 | rev | ordenar | uniq -c
Están sucediendo muchas cosas aquí.
- ls : enumera los archivos en el directorio
- rev : invierte el texto de los nombres de archivo.
- cut : Corta la cadena en la primera aparición del delimitador especificado «.». El texto posterior a esto se descarta.
- rev : invierte el texto restante , que es la extensión del nombre del archivo.
- ordenar : ordena la lista alfabéticamente.
- uniq : cuenta el número de cada entrada única en la lista .
El resultado muestra la lista de extensiones de archivo, ordenadas alfabéticamente con un recuento de cada tipo único.
Tubos con nombre
Hay otro tipo de tubería disponible para nosotros, llamadas tuberías con nombre. Las tuberías de los ejemplos anteriores se crean sobre la marcha mediante el shell cuando procesa la línea de comandos. Las tuberías se crean, se utilizan y luego se desechan. Son pasajeros y no dejan rastro de sí mismos. Sólo existen mientras se esté ejecutando el comando que los usa.
Las canalizaciones con nombre aparecen como objetos persistentes en el sistema de archivos, por lo que puede verlas usando ls. Son persistentes porque sobrevivirán a un reinicio de la computadora, aunque se descartarán todos los datos no leídos en ese momento.
Las canalizaciones con nombre se usaron mucho a la vez para permitir que diferentes procesos envíen y reciban datos, pero no los he visto usados de esa manera durante mucho tiempo. Sin duda, hay gente que todavía los usa con gran efecto, pero no he encontrado ninguno recientemente. Pero en aras de la integridad, o simplemente para satisfacer su curiosidad, así es como puede usarlos.
Las tuberías con nombre se crean con el mkfifocomando. Este comando creará una tubería con nombre llamada «geek-pipe» en el directorio actual.
mkfifo geek-pipe
Podemos ver los detalles de la tubería nombrada si usamos el lscomando con la -lopción (formato largo):
ls -l geek-pipe
El primer carácter de la lista es una «p», lo que significa que es una tubería. Si fuera una «d», significaría que el objeto del sistema de archivos es un directorio, y un guión «-» significaría que es un archivo normal.
Usar la tubería con nombre
Usemos nuestra pipa. Las tuberías sin nombre que usamos en nuestros ejemplos anteriores pasaron los datos inmediatamente desde el comando de envío al comando de recepción. Los datos enviados a través de una canalización con nombre permanecerán en la canalización hasta que se lean. Los datos se guardan realmente en la memoria, por lo que el tamaño de la tubería con nombre no variará en los lslistados, ya sea que haya datos o no.
Usaremos dos ventanas de terminal para este ejemplo. Usaré la etiqueta:
# Terminal 1
en una ventana de terminal y
# Terminal 2
en el otro, para que puedas diferenciarlos. El hash «#» le dice al shell que lo que sigue es un comentario y que lo ignore.
Tomemos la totalidad de nuestro ejemplo anterior y redirigamos eso a la tubería nombrada. Así que estamos usando canalizaciones con nombre y sin nombre en un comando:
ls | rev | cortar -d '.' -f1 | rev | ordenar | uniq -c> geek-pipe

No parecerá que suceda mucho. Sin embargo, puede notar que no regresa al símbolo del sistema, por lo que algo está sucediendo.
En la otra ventana de terminal, emita este comando:
gato <geek-pipe
Estamos redirigiendo el contenido de la tubería nombrada a cat, de modo que catse mostrará ese contenido en la segunda ventana de terminal. Aquí está el resultado:
Y verá que ha regresado al símbolo del sistema en la primera ventana de terminal.
Entonces, ¿qué acaba de pasar?
- Redirigimos algunos resultados a la tubería nombrada.
- La primera ventana de terminal no regresó al símbolo del sistema.
- Los datos permanecieron en la tubería hasta que se leyeron de la tubería en la segunda terminal.
- Regresamos al símbolo del sistema en la primera ventana de terminal.
Puede estar pensando que podría ejecutar el comando en la primera ventana de terminal como una tarea en segundo plano agregando un &al final del comando. Y tendrías razón. En ese caso, habríamos regresado al símbolo del sistema inmediatamente.
El objetivo de no utilizar el procesamiento en segundo plano fue resaltar que una tubería con nombre es un proceso de bloqueo . Poner algo en una tubería con nombre solo abre un extremo de la tubería. El otro extremo no se abre hasta que el programa de lectura extrae los datos. El kernel suspende el proceso en la primera ventana de terminal hasta que los datos se leen desde el otro extremo de la tubería.
El poder de las tuberías
Hoy en día, las tuberías con nombre son una especie de acto novedoso.
Las viejas tuberías de Linux, por otro lado, son una de las herramientas más útiles que puede tener en su kit de herramientas de ventana de terminal. La línea de comandos de Linux comienza a cobrar vida para usted, y obtiene un encendido completamente nuevo cuando puede orquestar una colección de comandos para producir una actuación cohesiva.
Sugerencia de partida: es mejor escribir sus comandos canalizados agregando un comando a la vez y haciendo que esa parte funcione, luego canalizando en el siguiente comando.