Tabla de contenidos

El sistema de archivos de Linux se basa en inodos. Estas piezas vitales del funcionamiento interno del sistema de archivos a menudo se malinterpretan. Veamos exactamente qué son y qué hacen.
Los elementos de un sistema de archivos
Por definición, un sistema de archivos necesita almacenar archivos y también contienen directorios. Los archivos se almacenan dentro de los directorios y estos directorios pueden tener subdirectorios. Algo, en algún lugar, tiene que registrar dónde se encuentran todos los archivos dentro del sistema de archivos, cómo se llaman, a qué cuentas pertenecen, qué permisos tienen y mucho más. Esta información se llama metadatos porque son datos que describen otros datos.
En el sistema de archivos ext4 de Linux , las estructuras de directorio y de inodo trabajan juntas para proporcionar un marco de apoyo que almacena todos los metadatos para cada archivo y directorio. Hacen los metadatos disponibles para cualquier persona que lo requiera, ya sea el núcleo, las aplicaciones de usuario, o utilidades de Linux, tales como , , y .lsstatdf
Inodos y tamaño del sistema de archivos
Si bien es cierto que hay un par de estructuras, un sistema de archivos requiere muchas más que eso. Hay miles y miles de cada estructura. Cada archivo y directorio requiere un inodo, y debido a que cada archivo está en un directorio, cada archivo también requiere una estructura de directorio. Las estructuras de directorio también se denominan entradas de directorio o «dentries».
Cada inodo tiene un número de inodo, que es único dentro de un sistema de archivos. El mismo número de inodo puede aparecer en más de un sistema de archivos. Sin embargo, el ID del sistema de archivos y el número de inodo se combinan para crear un identificador único, independientemente de cuántos sistemas de archivos estén montados en su sistema Linux.
Recuerde, en Linux, no monta un disco duro o una partición. Usted monta el sistema de archivos que está en la partición, por lo que es fácil tener varios sistemas de archivos sin darse cuenta. Si tiene varios discos duros o particiones en un solo disco, tiene más de un sistema de archivos. Pueden ser del mismo tipo, todos ext4, por ejemplo, pero seguirán siendo sistemas de archivos distintos.
Todos los inodos se mantienen en una tabla. Usando un número de inodo, el sistema de archivos calcula fácilmente el desplazamiento en la tabla de inodo en la que se encuentra ese inodo. Puede ver por qué la «i» en inodo significa índice.
La variable que contiene el número de inodo se declara en el código fuente como un entero largo sin signo de 32 bits. Esto significa que el número de inodo es un valor entero con un tamaño máximo de 2 ^ 32, que se calcula en 4.294.967.295, más de 4 mil millones de inodos.
Ese es el máximo teórico. En la práctica, el número de inodos en un sistema de archivos ext4 se determina cuando el sistema de archivos se crea con una proporción predeterminada de un inodo por cada 16 KB de capacidad del sistema de archivos. Las estructuras de directorio se crean sobre la marcha cuando el sistema de archivos está en uso, ya que los archivos y directorios se crean dentro del sistema de archivos.
Hay un comando que puede usar para ver cuántos inodos hay en un sistema de archivos en su computadora. La -iopción (inodos) del dfcomando le indica que muestre su salida en números de inodos .
Vamos a ver el sistema de archivos en la primera partición en el primer disco duro, entonces escribimos lo siguiente:
df -i / dev / sda1

La salida nos da:
- Sistema de archivos : el sistema de archivos sobre el que se informa.
- Inodos : el número total de inodos en este sistema de archivos.
- IUsed : el número de inodos en uso.
- IFree : el número de inodos restantes disponibles para su uso.
- IUse% : el porcentaje de inodos usados.
- Montado en : el punto de montaje para este sistema de archivos.
Hemos utilizado el 10 por ciento de los inodos en este sistema de archivos. Los archivos se almacenan en el disco duro en bloques de disco. Cada inodo apunta a los bloques de disco que almacenan el contenido del archivo que representan. Si tiene millones de archivos diminutos, puede quedarse sin inodos antes de quedarse sin espacio en el disco duro. Sin embargo, ese es un problema muy difícil de encontrar.
En el pasado, algunos servidores de correo que almacenaban mensajes de correo electrónico como archivos discretos (que rápidamente conducían a grandes colecciones de archivos pequeños) tenían este problema. Sin embargo, cuando esas aplicaciones cambiaron su back-end a bases de datos, esto resolvió el problema. El sistema doméstico promedio no se quedará sin inodos, lo cual es bueno porque, con el sistema de archivos ext4, no puede agregar más inodos sin reinstalar el sistema de archivos.
Para ver el tamaño de los bloques de disco en su sistema de archivos , puede usar el blockdevcomando con la --getbszopción (obtener tamaño de bloque):
sudo blockdev --getbsz / dev / sda

El tamaño del bloque es 4096 bytes.
Usemos la -Bopción (tamaño de bloque) para especificar un tamaño de bloque de 4096 bytes y verifiquemos el uso regular del disco:
df -B 4096 / dev / sda1

Esta salida nos muestra:
- Sistema de archivos : el sistema de archivos sobre el que informamos.
- Bloques de 4K : el número total de bloques de 4 KB en este sistema de archivos.
- Usado : cuántos bloques 4K están en uso.
- Disponible : la cantidad de bloques de 4 KB restantes que están disponibles para su uso.
- % De uso : el porcentaje de bloques de 4 KB que se han utilizado.
- Montado en : el punto de montaje para este sistema de archivos.
En nuestro ejemplo, el almacenamiento de archivos (y el almacenamiento de inodos y estructuras de directorios) ha utilizado el 28 por ciento del espacio en este sistema de archivos, al costo del 10 por ciento de los inodos, por lo que estamos en buena forma.
Metadatos de inode
Para ver el número de inodo de un archivo, podemos usar lscon la -iopción (inode):
ls -i geek.txt

El número de inodo para este archivo es 1441801, por lo que este inodo contiene los metadatos para este archivo y, tradicionalmente, los punteros a los bloques de disco donde reside el archivo en el disco duro. Si el archivo está fragmentado, es muy grande o ambos, algunos de los bloques a los que apunta el inodo pueden contener más punteros a otros bloques de disco. Y algunos de esos otros bloques de disco también pueden contener punteros a otro conjunto de bloques de disco. Esto supera el problema de que el inodo tiene un tamaño fijo y puede contener un número finito de punteros a bloques de disco.
Ese método fue reemplazado por un nuevo esquema que hace uso de «extensiones». Estos registran el bloque inicial y final de cada conjunto de bloques contiguos que se utilizan para almacenar el archivo. Si el archivo no está fragmentado, solo tiene que almacenar el primer bloque y la longitud del archivo. Si el archivo está fragmentado, debe almacenar el primer y último bloque de cada parte del archivo. Este método es (obviamente) más eficiente.
Si desea ver si su sistema de archivos usa punteros o extensiones de bloque de disco, puede mirar dentro de un inodo. Para hacerlo, usaremos el debugfscomando con la -Ropción (solicitud) y le pasaremos el inodo del archivo de interés . Esto solicita debugfs usar su comando interno «stat» para mostrar el contenido del inodo. Debido a que los números de inodo solo son únicos dentro de un sistema de archivos, también debemos indicarle debugfs al sistema de archivos en el que reside el inodo.
Así es como se vería este comando de ejemplo:
sudo debugfs -R "stat <1441801>" / dev / sda1
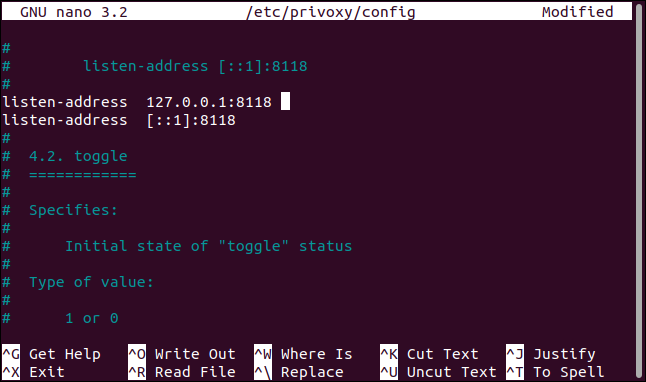
Como se muestra a continuación, el debugfscomando extrae la información del inodo y nos la presenta en less:
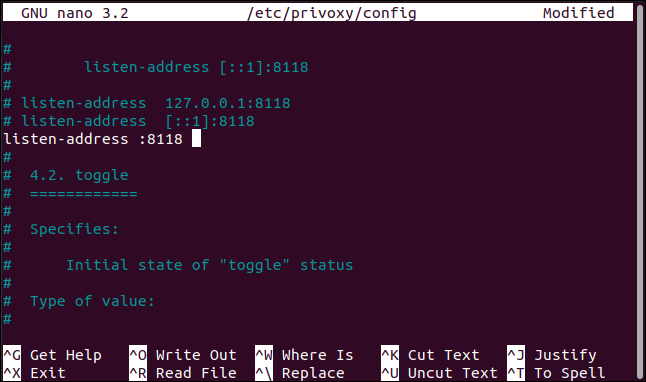
Se nos muestra la siguiente información:
- Inode : el número del inodo que estamos viendo.
- Tipo : este es un archivo normal, no un directorio ni un enlace simbólico.
- Modo : los permisos del archivo en octal .
- Banderas : Indicadores que representan diferentes características o funcionalidades. El 0x80000 es el indicador de «extensiones» (más sobre esto a continuación).
- Generación : un sistema de archivos de red (NFS) lo usa cuando alguien accede a sistemas de archivos remotos a través de una conexión de red como si estuvieran montados en la máquina local. Los números de inodo y generación se utilizan como una forma de identificador de archivo.
- Versión : la versión de inodo.
- Usuario : el propietario del archivo.
- Grupo : el propietario del grupo del archivo.
- Proyecto : Siempre debe ser cero.
- Tamaño : el tamaño del archivo.
- Archivo ACL : la lista de control de acceso a archivos. Estos fueron diseñados para permitirle dar acceso controlado a personas que no están en el grupo de propietarios.
- Enlaces : el número de enlaces físicos al archivo.
- Blockcount : la cantidad de espacio en el disco duro asignado a este archivo, expresada en fragmentos de 512 bytes. A nuestro archivo se le han asignado ocho de estos, que son 4.096 bytes. Entonces, nuestro archivo de 98 bytes se encuentra dentro de un solo bloque de disco de 4.096 bytes.
- Fragmento : este archivo no está fragmentado. (Esta es una bandera obsoleta).
- Ctime : la hora a la que se creó el archivo.
- Atime : la hora a la que se accedió por última vez a este archivo.
- Mtime : la hora a la que se modificó por última vez este archivo.
- Crtime : la hora a la que se creó el archivo.
- Tamaño de los campos de inodo adicionales : el sistema de archivos ext4 introdujo la capacidad de asignar un inodo en disco más grande en el momento del formateo. Este valor es el número de bytes adicionales que utiliza el inodo. Este espacio adicional también se puede utilizar para acomodar los requisitos futuros de nuevos núcleos o para almacenar atributos extendidos.
- Suma de comprobación de inodo: una suma de comprobación para este inodo, que permite detectar si el inodo está dañado.
- Extensiones : si se utilizan extensiones (en ext4, lo son, de forma predeterminada), los metadatos relacionados con el uso de bloques de disco de los archivos tienen dos números que indican los bloques de inicio y finalización de cada parte de un archivo fragmentado. Esto es más eficaz que almacenar todos los bloques de disco ocupados por cada parte de un archivo. Tenemos una extensión porque nuestro archivo pequeño se encuentra en un bloque de disco en este desplazamiento de bloque.
¿Dónde está el nombre del archivo?
Ahora tenemos mucha información sobre el archivo, pero, como habrás notado, no obtuvimos el nombre del archivo. Aquí es donde entra en juego la estructura de directorios. En Linux, al igual que un archivo, un directorio tiene un inodo. Sin embargo, en lugar de apuntar a bloques de disco que contienen datos de archivo, un inodo de directorio apunta a bloques de disco que contienen estructuras de directorio.
En comparación con un inodo, una estructura de directorio contiene una cantidad limitada de información sobre un archivo . Solo contiene el número de inodo del archivo, el nombre y la longitud del nombre.
El inodo y la estructura del directorio contienen todo lo que usted (o una aplicación) necesita saber sobre un archivo o directorio. La estructura del directorio está en un bloque de disco de directorio, por lo que sabemos en qué directorio se encuentra el archivo. La estructura del directorio nos da el nombre del archivo y el número de inodo. El inodo nos dice todo lo demás sobre el archivo, incluidas las marcas de tiempo, los permisos y dónde encontrar los datos del archivo en el sistema de archivos.
Inodos de directorio
Puede ver el número de inodo de un directorio tan fácilmente como puede verlos para los archivos.
En el siguiente ejemplo, usaremos ls con las opciones -l(formato largo), -i(inodo) y -d(directorio), y miraremos el workdirectorio:
ls -lid work /

Debido a que usamos la -dopción (directorio), lsinforma sobre el directorio en sí, no sobre su contenido. El inodo para este directorio es 1443016.
Para repetir eso para el homedirectorio, escribimos lo siguiente:
ls -lid ~
El inodo para el homedirectorio es 1447510 y el workdirectorio está en el directorio de inicio. Ahora, veamos el contenido del workdirectorio. En lugar de la -dopción (directorio), usaremos la -aopción (todos). Esto nos mostrará las entradas del directorio que suelen estar ocultas.
Escribimos lo siguiente:
ls -lia trabajo /
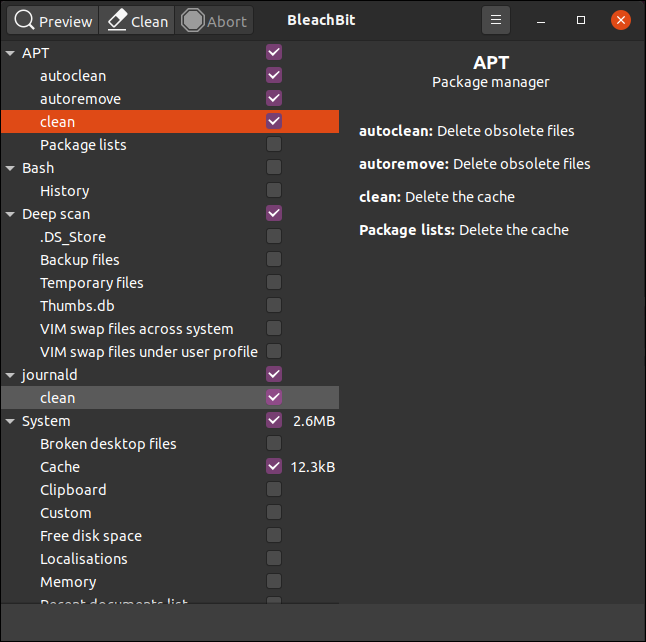
Debido a que usamos la -aopción (todos), se muestran las entradas de un solo punto (.) Y de doble punto (..). Estas entradas representan el directorio en sí (punto único) y su directorio padre (punto doble).
Si observa el número de inodo para la entrada de un solo punto, verá que es 1443016, el mismo número de inodo que obtuvimos cuando descubrimos el número de inodo para el workdirectorio. Además, el número de inodo para la entrada de doble punto es el mismo que el número de inodo para el homedirectorio.
Es por eso que puede usar el cd ..comando para subir un nivel en el árbol de directorios. Del mismo modo, cuando antepone el nombre de una aplicación o script ./, le indica al shell desde dónde iniciar la aplicación o el script.
Inodos y enlaces
Como hemos visto, se requieren tres componentes para tener un archivo bien formado y accesible en el sistema de archivos: el archivo, la estructura del directorio y el inodo. El archivo son los datos almacenados en el disco duro, la estructura del directorio contiene el nombre del archivo y su número de inodo, y el inodo contiene todos los metadatos del archivo.
Los enlaces simbólicos son entradas del sistema de archivos que parecen archivos, pero en realidad son atajos que apuntan a un archivo o directorio existente. Veamos cómo gestionan esto y cómo se utilizan los tres elementos para lograrlo.
Digamos que tenemos un directorio con dos archivos: uno es un script y el otro es una aplicación, como se muestra a continuación.

Podemos usar el comando ln y la -sopción (simbólica) para crear un enlace suave al archivo de script, así:
ls -s my_script geek.sh
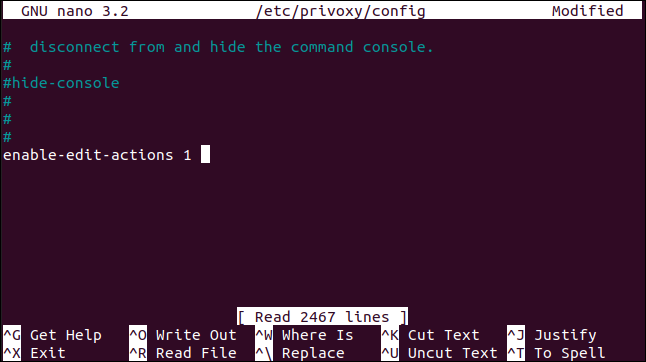
Hemos creado un enlace a my_script.shllamado geek.sh. Podemos escribir lo siguiente y usarlo ls para ver los dos archivos de script:
ls -li * .sh
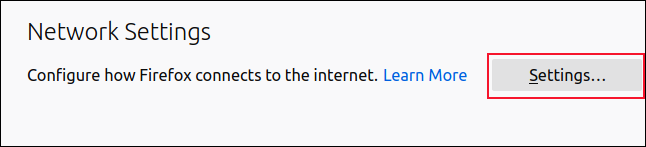
La entrada para geek.sh aparece en azul. El primer carácter de las banderas de permisos es una «l» para el enlace y los ->puntos a my_script.sh. Todo esto indica que geek.shes un enlace.
Como probablemente espera, los dos archivos de script tienen diferentes números de inodo. Sin embargo, lo que podría ser más sorprendente es que el enlace flexible geek.sh, no tiene los mismos permisos de usuario que el archivo de script original. De hecho, los permisos para geek.shson mucho más liberales: todos los usuarios tienen permisos completos.
La estructura del directorio geek.shcontiene el nombre del enlace y su inodo. Cuando intenta utilizar el enlace, se hace referencia a su inodo, como un archivo normal. El inodo de enlace apuntará a un bloque de disco, pero en lugar de contener datos de contenido de archivo, el bloque de disco contiene el nombre del archivo original. El sistema de archivos redirige al archivo original.
Eliminaremos el archivo original y veremos qué sucede cuando escribimos lo siguiente para ver el contenido de geek.sh:
rm my_script.sh
gato geek.sh
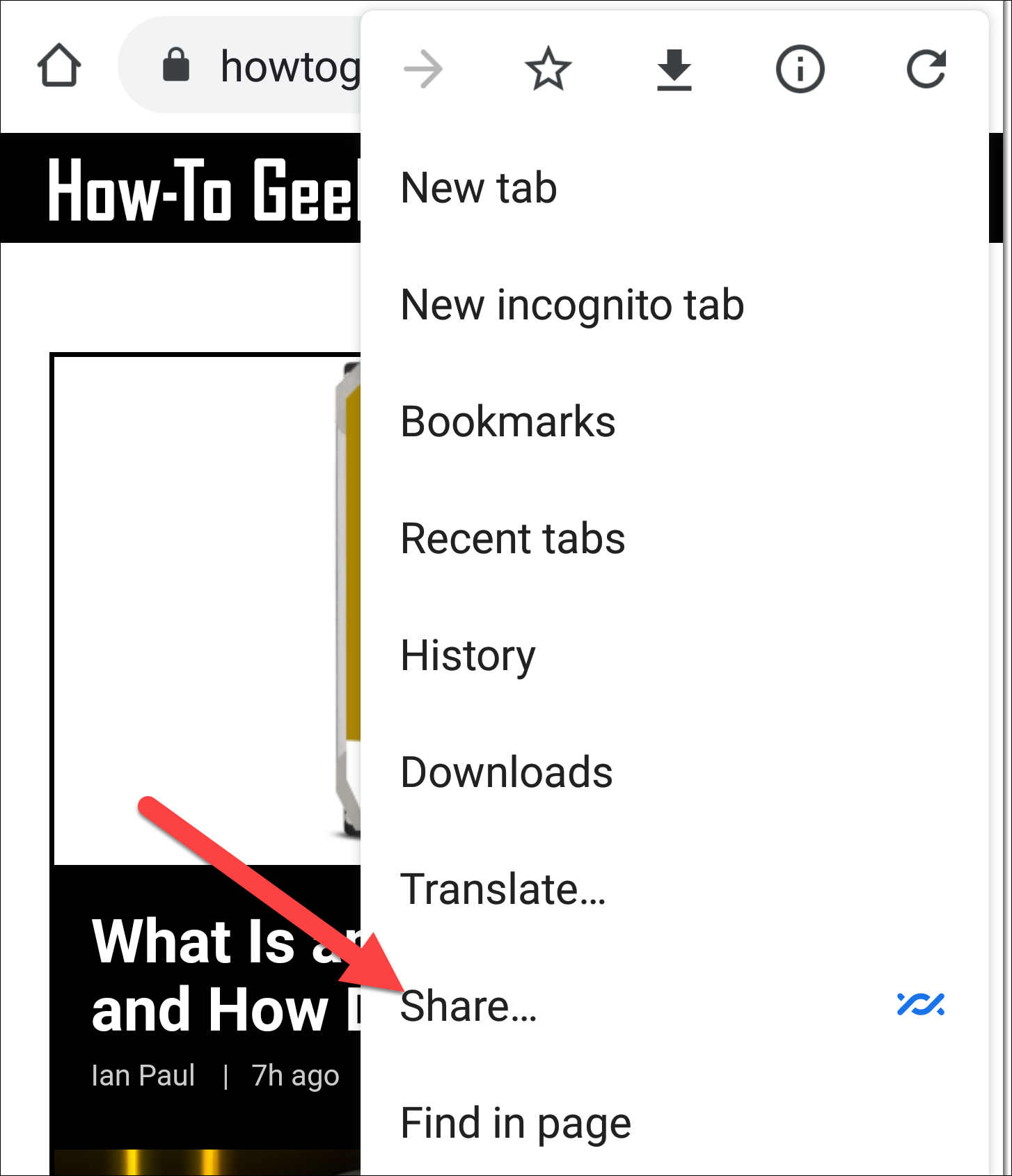
El enlace simbólico está roto y la redirección falla.
Ahora escribimos lo siguiente para crear un enlace duro al archivo de la aplicación:
En una aplicación especial, una aplicación geek
Para ver los inodos de estos dos archivos, escribimos lo siguiente:
ls -li
Ambos parecen archivos normales. Nada geek-appindica que sea un enlace en la forma lsen que lo geek.shhizo la lista . Además, geek-app tiene los mismos permisos de usuario que el archivo original. Sin embargo, lo que podría sorprender es que ambas aplicaciones tienen el mismo número de inodo: 1441797.
La entrada de directorio para geek-appcontiene el nombre “geek-app” y un número de inodo, pero es el mismo que el número de inodo del archivo original. Entonces, tenemos dos entradas del sistema de archivos con diferentes nombres que apuntan al mismo inodo. De hecho, cualquier número de elementos puede apuntar al mismo inodo.
Escribiremos lo siguiente y usaremos el statprograma para ver el archivo de destino :
estadística-aplicación especial
Vemos que dos enlaces duros apuntan a este archivo. Esto se almacena en el inodo.
En el siguiente ejemplo, eliminamos el archivo original e intentamos usar el enlace con una contraseña secreta y segura :
rm aplicación especial
./geek-app correcthorsebatterystaple
Sorprendentemente, la aplicación se ejecuta como se esperaba, pero ¿cómo? Funciona porque, cuando elimina un archivo, el inodo puede reutilizarse libremente. La estructura del directorio está marcada con un número de inodo de cero, y los bloques de disco están disponibles para que se almacene otro archivo en ese espacio.
Sin embargo, si el número de enlaces físicos al inodo es mayor que uno, el recuento de enlaces físicos se reduce en uno y el número de inodo de la estructura de directorios del archivo eliminado se establece en cero. El contenido del archivo en el disco duro y el inodo todavía está disponible para los enlaces duros existentes.
Escribiremos lo siguiente y usaremos stat una vez más, esta vez en geek-app:
stat geek-app
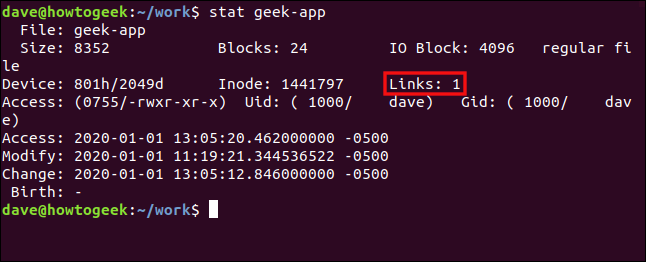
Estos detalles se extraen del mismo inodo (1441797) que el statcomando anterior . El recuento de enlaces se redujo en uno.
Debido a que solo tenemos un enlace duro a este inodo, si lo eliminamos geek-app, realmente eliminaría el archivo. El sistema de archivos liberará el inodo y marcará la estructura del directorio con un inodo de cero. Un nuevo archivo puede sobrescribir el almacenamiento de datos en el disco duro.
Gastos generales de Inode
es un sistema ordenado, pero hay gastos generales. Para leer un archivo, el sistema de archivos debe hacer todo lo siguiente:
- Encuentre la estructura de directorio correcta
- Leer el número de inodo
- Encuentra el inodo correcto
- Leer la información del inodo
- Siga los enlaces de inodo o las extensiones a los bloques de disco relevantes
- Leer los datos del archivo
Es necesario saltar un poco más si los datos no son contiguos.
Imagine el trabajo que debe realizarse para ls realizar una lista de archivos de formato largo de muchos archivos. Hay un montón de ida y vuelta solo para lsobtener la información que necesita para generar su salida.
Por supuesto, acelerar el acceso al sistema de archivos es la razón por la que Linux intenta realizar la mayor cantidad posible de almacenamiento en caché de archivos preventivo. Esto ayuda mucho, pero a veces, como con cualquier sistema de archivos, los gastos generales pueden hacerse evidentes.
Ahora sabrás por qué.