Tabla de contenidos

¿Alguna vez buscó algo en Google y se preguntó: «¿Cómo sabe dónde buscar?» La respuesta son los «rastreadores web», que buscan en la web y la indexan para que pueda encontrar cosas fácilmente en línea. Te lo explicaremos.
Motores de búsqueda y rastreadores
Cuando realiza una búsqueda utilizando una palabra clave en un motor de búsqueda como Google o Bing , el sitio examina billones de páginas para generar una lista de resultados relacionados con ese término. ¿Cómo exactamente estos motores de búsqueda tienen todas estas páginas archivadas, saben cómo buscarlas y generan estos resultados en segundos?
La respuesta son los rastreadores web, también conocidos como arañas. Se trata de programas automatizados (a menudo denominados «robots» o «bots») que «rastrean» o navegan por la web para poder agregarlos a los motores de búsqueda. Estos robots indexan sitios web para crear una lista de páginas que eventualmente aparecerán en sus resultados de búsqueda.
Los rastreadores también crean y almacenan copias de estas páginas en la base de datos del motor, lo que le permite realizar búsquedas casi instantáneamente. También es la razón por la que los motores de búsqueda a menudo incluyen versiones en caché de sitios en sus bases de datos.
Selección y mapas del sitio
Entonces, ¿cómo eligen los rastreadores qué sitios web rastrear? Bueno, el escenario más común es que los propietarios de sitios web quieran que los motores de búsqueda rastreen sus sitios. Pueden lograrlo solicitando a Google, Bing, Yahoo u otro motor de búsqueda que indexe sus páginas. Este proceso varía de un motor a otro. Además, los motores de búsqueda seleccionan con frecuencia sitios web populares y bien vinculados para rastrear mediante el seguimiento de la cantidad de veces que una URL está vinculada en otros sitios públicos.
Los propietarios de sitios web pueden utilizar ciertos procesos para ayudar a los motores de búsqueda a indexar sus sitios web, como
cargar un mapa del sitio. Este es un archivo que contiene todos los enlaces y páginas que forman parte de su sitio web. Normalmente se usa para indicar qué páginas le gustaría indexar.
Una vez que los motores de búsqueda ya hayan rastreado un sitio web una vez, lo volverán a rastrear automáticamente. La frecuencia varía según la popularidad de un sitio web, entre otras métricas. Por lo tanto, los propietarios de sitios mantienen con frecuencia mapas de sitios actualizados para que los motores sepan qué nuevos sitios web indexar.
Los robots y el factor de cortesía

¿Qué pasa si un sitio web no quiere que algunas o todas sus páginas aparezcan en un motor de búsqueda? Por ejemplo, es posible que no desee que las personas busquen una página exclusiva para miembros o que vean su página de error 404 . Aquí es donde entra en juego la lista de exclusión de rastreo, también conocida como robots.txt. Este es un archivo de texto simple que dicta a los rastreadores qué páginas web deben excluir de la indexación.
Otra razón por la que robots.txt es importante es que los rastreadores web pueden tener un efecto significativo en el rendimiento del sitio. Debido a que los rastreadores esencialmente descargan todas las páginas de su sitio web, consumen recursos y pueden causar ralentizaciones. Llegan en momentos impredecibles y sin aprobación. Si no necesita que sus páginas se indexen repetidamente, detener los rastreadores podría ayudar a reducir parte de la carga de su sitio web. Afortunadamente, la mayoría de los rastreadores dejan de rastrear determinadas páginas según las reglas del propietario del sitio.
Magia de metadatos
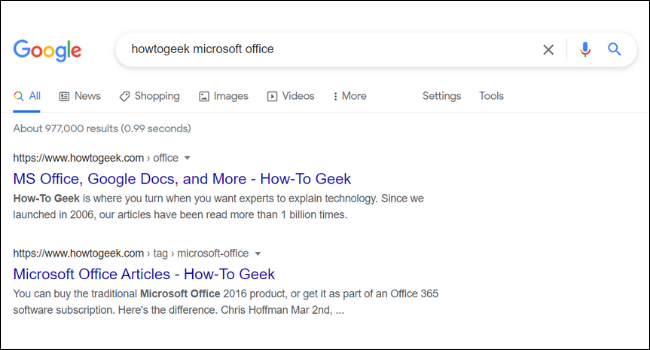
Debajo de la URL y el título de cada resultado de búsqueda en Google, encontrará una breve descripción de la página. Estas descripciones se denominan fragmentos. Puede notar que el fragmento de una página en Google no siempre se alinea con el contenido real del sitio web. Esto se debe a que muchos sitios web tienen algo llamado » metaetiquetas » , que son descripciones personalizadas que los propietarios de sitios agregan a sus páginas.
Los propietarios de sitios a menudo presentan descripciones de metadatos tentadoras escritas para que quieras hacer clic en un sitio web. Google también enumera otra metainformación, como precios y disponibilidad de stock. Esto es especialmente útil para quienes ejecutan sitios web de comercio electrónico.
Tu búsqueda
La búsqueda en la web es una parte esencial del uso de Internet. Buscar en la web es una excelente manera de descubrir nuevos sitios web, tiendas, comunidades e intereses. Todos los días, los rastreadores web visitan millones de páginas y las agregan a los motores de búsqueda. Si bien los rastreadores tienen algunas desventajas, como ocupar los recursos del sitio, son invaluables tanto para los propietarios como para los visitantes.

