Los comandos dfy duinforman sobre el uso del espacio en disco desde el shell de Bash utilizado en Linux, macOS y muchos otros sistemas operativos similares a Unix. Estos comandos le permiten identificar fácilmente qué está consumiendo el almacenamiento de su sistema.
Visualización del espacio en disco total, disponible y utilizado
Bash contiene dos comandos útiles relacionados con el espacio en disco. Para averiguar el espacio en disco disponible y utilizado, utilice df(sistemas de archivos de disco, a veces llamado disco libre). Para descubrir qué está ocupando el espacio en disco usado, use du(uso de disco).
Escriba dfy presione Intro en una ventana de terminal Bash para comenzar. Verá una gran cantidad de resultados similares a la captura de pantalla a continuación. El uso dfsin opciones mostrará el espacio disponible y utilizado para todos los sistemas de archivos montados. A primera vista, puede parecer impenetrable, pero es bastante fácil de entender.
df
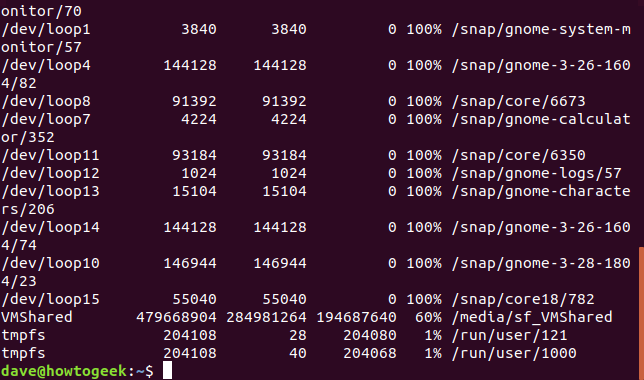
Cada línea de la pantalla se compone de seis columnas.
- Sistema de archivos: el nombre de este sistema de archivos.
- 1K-Blocks: la cantidad de 1K bloques que están disponibles en este sistema de archivos.
- Usado: el número de bloques de 1K que se han usado en este sistema de archivos.
- Disponible: el número de bloques de 1K que no se utilizan en este sistema de archivos.
- Use%: la cantidad de espacio usado en este sistema de archivos expresada como porcentaje.
- Archivo: el nombre del sistema de archivos, si se especifica en la línea de comando.
- Montado en: el punto de montaje del sistema de archivos.
Puede reemplazar los recuentos de bloques de 1K con una salida más útil utilizando la -Bopción (tamaño de bloque). Para usar esta opción, escriba df,un espacio y luego -Buna letra de la lista de K, M, G, T, P, E, Z o Y. Estas letras representan kilo, mega, giga, tera, peta, exa, valores zeta y yotta del múltiplo de la escala 1024.
Por ejemplo, para ver las cifras de uso del disco en megabytes, usaría el siguiente comando. Tenga en cuenta que no hay espacio entre B y M.
df -BM
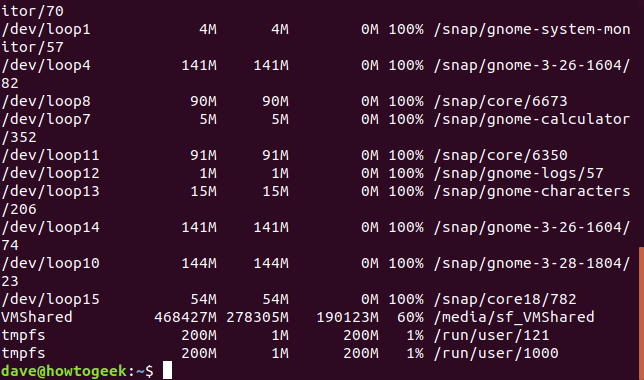
La -hopción (legible por humanos) indica dfque se use la unidad más aplicable para el tamaño de cada sistema de archivos. En la siguiente salida, observe que hay sistemas de archivos con tamaños de gigabytes, megabytes e incluso kilobytes.
df -h
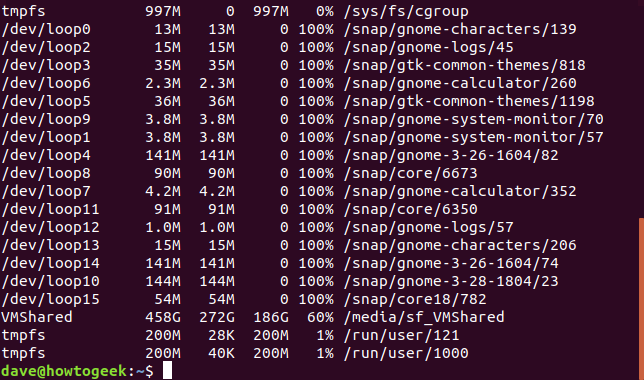
Si necesita ver la información representada en números de inodos, use la -iopción (inodos). Un inodo es una estructura de datos utilizada por los sistemas de archivos de Linux para describir archivos y almacenar metadatos sobre ellos. En Linux, los inodos contienen datos como el nombre, la fecha de modificación, la posición en el disco duro, etc. para cada archivo y directorio. Esto no será útil para la mayoría de las personas, pero los administradores del sistema a veces deben consultar este tipo de información.
df -i
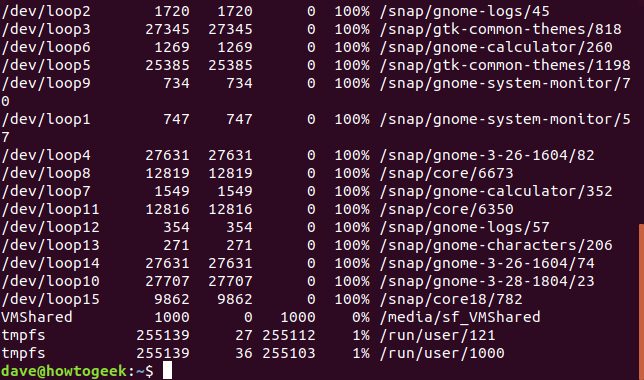
A menos que se le indique que no lo dfhaga , proporcionará información sobre todos los sistemas de archivos montados. Esto puede provocar una pantalla desordenada con mucha salida. Por ejemplo, las /dev/loopentradas en las listas son pseudo sistemas de archivos que permiten montar un archivo como si fuera una partición. Si utiliza el nuevo snapmétodo de instalación de aplicaciones de Ubuntu , puede adquirir muchas de ellas. El espacio disponible en estos siempre será 0 porque no son realmente un sistema de archivos, por lo que no necesitamos verlos.
Podemos decirle dfque excluya sistemas de archivos de un tipo específico. Para hacerlo, necesitamos saber qué tipo de sistema de archivos deseamos excluir. La -Topción (tipo de impresión) nos dará esa información. Instruye dfpara incluir el tipo de sistema de archivos en la salida.
df -T
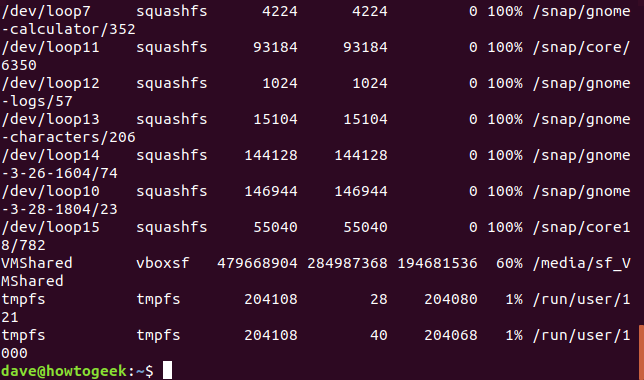
Las /dev/loopentradas son todos los squashfssistemas de archivos. Podemos excluirlos con el siguiente comando:
df -x squashfs
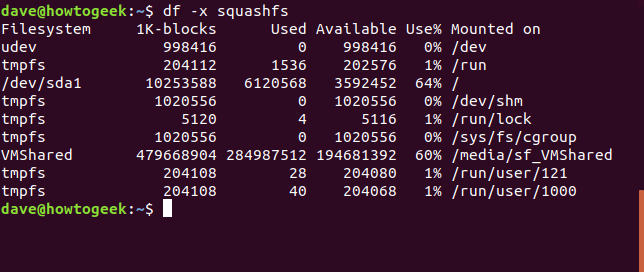
Eso nos da una salida más manejable. Para obtener un total, podemos agregar la --totalopción.
df -x squashfs --total
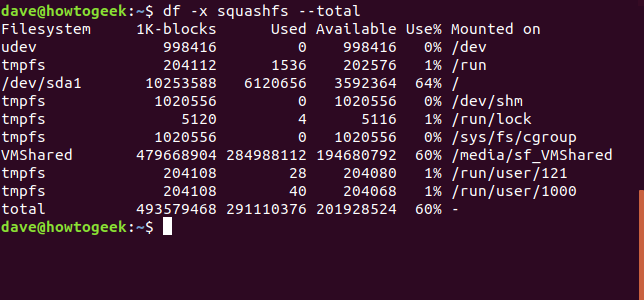
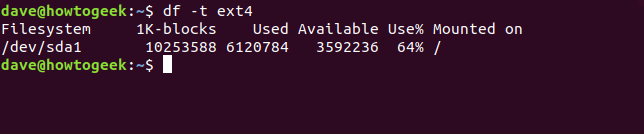
Podemos pedir dfque solo se incluyan sistemas de archivos de un tipo en particular, usando la -topción (tipo).
df -t ext4
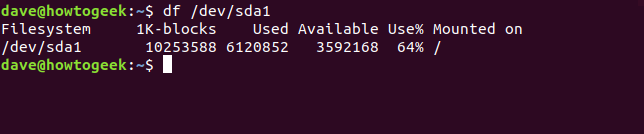
Si queremos ver los tamaños de un conjunto de sistemas de archivos, podemos especificarlos por nombre. Los nombres de las unidades en Linux están alfabéticos. Se llama a la primera unidad /dev/sda, a la segunda /dev/sdb, y así sucesivamente. Las particiones están numeradas. También lo /dev/sda1es la primera partición en la unidad /dev/sda. Decimos dfque devuelva información sobre un sistema de archivos en particular pasando el nombre del sistema de archivos como parámetro de comando. Veamos la primera partición del primer disco duro.
df / dev / sda1
Tenga en cuenta que puede utilizar comodines en el nombre del sistema de archivos, donde *representa cualquier conjunto de caracteres y ?representa cualquier carácter individual. Entonces, para ver todas las particiones en la primera unidad, podríamos usar:
df / dev / sda *
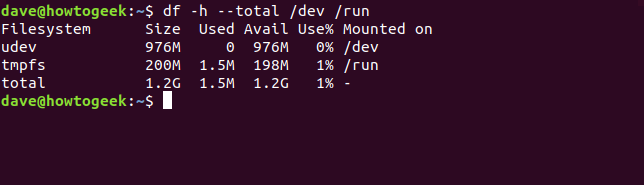
Podemos solicitar dfun informe sobre un conjunto de sistemas de archivos con nombre. Él nos están solicitando los tamaños de las /devy /runlos sistemas de archivos, y nos gustaría un total.
df -h --total / dev / run
Para personalizar aún más la pantalla, podemos decir dfqué columnas incluir. Para hacerlo, use la --outputopción y proporcione una lista separada por comas de los nombres de columna requeridos. Asegúrese de no incluir espacios en la lista separada por comas.
- fuente: el nombre del sistema de archivos.
- fstype: el tipo de sistema de archivos.
- itotal: el tamaño del sistema de archivos en inodos.
- iused: el espacio utilizado en el sistema de archivos en inodos.
- iavail: El espacio disponible en el sistema de archivos en inodos.
- ipcent: El porcentaje de espacio utilizado en el sistema de archivos en inodos, como porcentaje.
- tamaño: El tamaño del sistema de archivos, por defecto en bloques de 1K.
- utilizado: El espacio utilizado en el sistema de archivos, por defecto en bloques de 1K.
- disponibilidad: el espacio disponible en el sistema de archivos, por defecto en bloques de 1K.
- pcent: El porcentaje de espacio utilizado en el sistema de archivos en inodos, por defecto en bloques de 1K.
- archivo: el nombre del sistema de archivos si se especifica en la línea de comando.
- target: el punto de montaje para el sistema de archivos.
Vamos a pedir df al informe sobre la primera partición en el primer disco, con números legibles por humanos, y con la fuente de columnas, fstype, tamaño, utilizado, en vano, y pcent:
df -h / dev / sda1 --output = source, fstype, size, used, avail, pcent
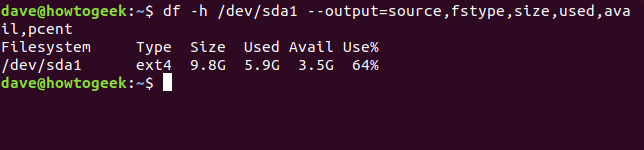
Los comandos largos son candidatos perfectos para convertirse en un alias. Podemos crear un alias dfc(para df custom) escribiendo lo siguiente y presionando Enter:
alias dfc = "df -h / dev / sda1 --output = source, fstype, size, used, avail, pcent"
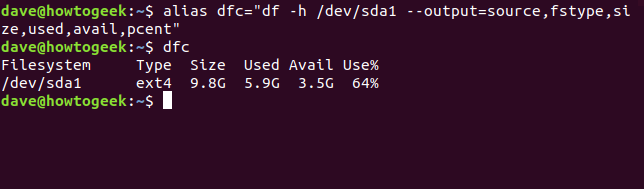
Escribir dfcy presionar enter tendrá el mismo efecto que escribir el comando largo. Para que este alias sea permanente, agréguelo a su archivo o ..bashrc.bash_aliases
Hemos estado buscando formas de refinar la salida dfpara que la información que muestra coincida con sus requisitos. Si desea tomar el enfoque opuesto y dfdevolver toda la información, puede usar la -aopción (todos) y la --outputopción que se muestra a continuación. La -aopción (todos) pide dfincluir todos los sistemas de archivos, y usar la --outputopción sin una lista de columnas separadas por comas hace dfque se incluyan todas las columnas.
df -a --salida
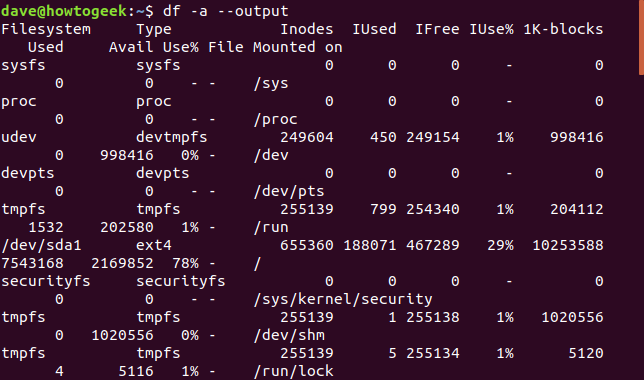
Canalizar la salida a dftravés del lesscomando es una forma conveniente de revisar la gran cantidad de salida que esto puede producir.
df -a --output | Menos
Averiguar qué ocupa el espacio en disco usado
Investiguemos un poco y descubramos qué está ocupando espacio en esta PC. Comenzaremos con uno de nuestros dfcomandos.
df -h -t ext4

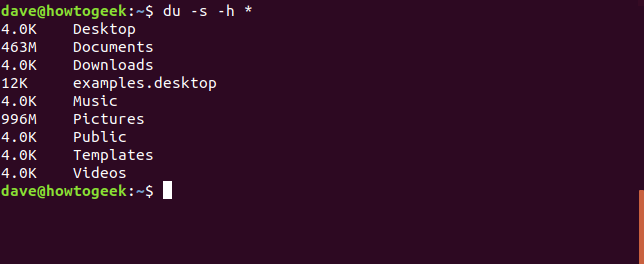
Se utiliza un 78% de espacio en disco en la primera partición del primer disco duro. Podemos usar el ducomando para mostrar qué carpetas contienen la mayor cantidad de datos. Emitir el ducomando sin opciones mostrará una lista de todos los directorios y subdirectorios debajo del directorio en el que duse emitió el comando. Si lo hace desde su carpeta de inicio, la lista será muy larga.
du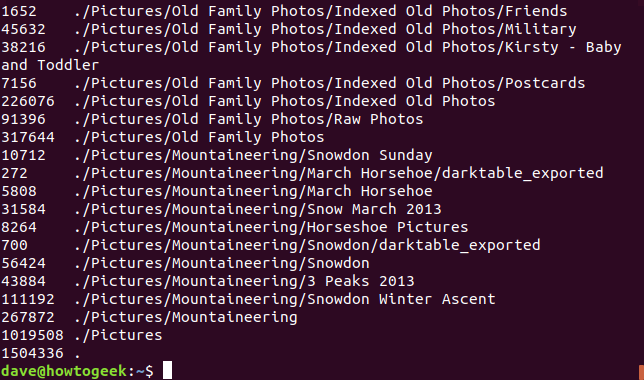
El formato de salida es muy sencillo. Cada línea muestra el tamaño y el nombre de un directorio. Por defecto, el tamaño se muestra en bloques de 1K. Para forzar el duuso de un tamaño de bloque diferente, use la -Bopción (tamaño de bloque). Para utilizar esta opción du, escriba un espacio y luego -Buna letra de la lista de K, M, G, T, P, E, Z e Y, como hicimos anteriormente para df. Para usar bloques de 1M, use este comando:
du -BM
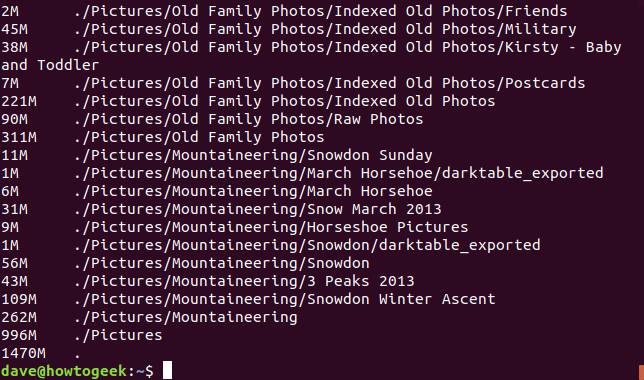
Al igual que df, dutiene una opción legible por humanos -h, que utiliza un rango de tamaños de bloque de acuerdo con el tamaño de cada directorio.
du -h
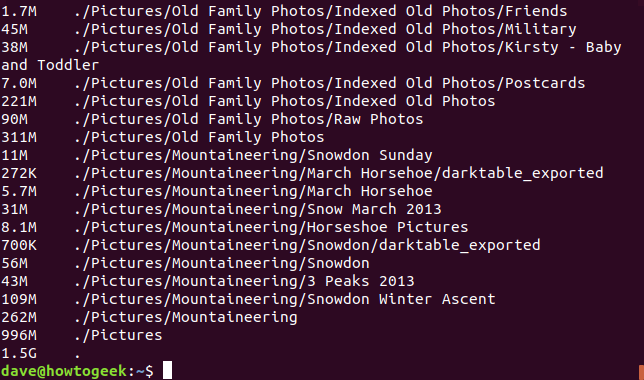
La -sopción (resumir) da un total para cada directorio sin mostrar los subdirectorios dentro de cada directorio. El siguiente comando solicita dudevolver información en formato de resumen, en números legibles por humanos, para todos los directorios (*) debajo del directorio de trabajo actual.
du -h -s *
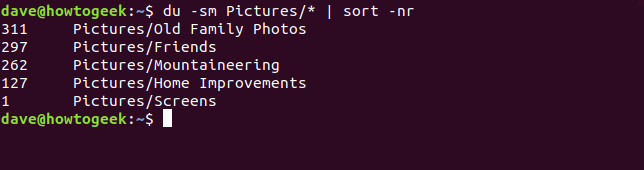
La carpeta de imágenes contiene la mayor cantidad de datos con diferencia. Podemos pedir dua ordenar las carpetas de tamaño de mayor a menor.
du -sm Imágenes / * | sort -nr
Al refinar la información devuelta por dfy du, es fácil averiguar cuánto espacio en el disco duro está en uso y qué está ocupando ese espacio. Luego, puede tomar una decisión informada sobre cómo mover algunos datos a otro almacenamiento, agregar otro disco duro a su computadora o eliminar datos redundantes.
Estos comandos tienen muchas opciones. Describimos las opciones más útiles aquí, pero puede ver una lista completa de las opciones para el comando df y para el comando du en las páginas de manual de Linux.