Tabla de contenidos

¿Se pregunta qué hacen esas extrañas cadenas de símbolos en Linux? ¡Te dan magia de línea de comandos! Te enseñaremos cómo lanzar hechizos de expresión regular y subir de nivel tus habilidades de línea de comandos.
¿Qué son las expresiones regulares?
Las expresiones regulares ( regexes ) son una forma de encontrar secuencias de caracteres coincidentes. Usan letras y símbolos para definir un patrón que se busca en un archivo o secuencia. Hay varios sabores diferentes de expresiones regulares. Vamos a ver la versión utilizada en las utilidades y comandos comunes de Linux, como grepel comando que imprime líneas que coinciden con un patrón de búsqueda .
Se han escrito libros completos sobre expresiones regulares, por lo que este tutorial es simplemente una introducción. Hay expresiones regulares básicas y extendidas, y usaremos las extendidas aquí.
Para usar las expresiones regulares extendidas con grep, debe usar la -Eopción (extendida). Debido a que esto se vuelve agotador muy rápidamente, egrepse creó el comando. El egrepcomando es el mismo que la grep -Ecombinación, pero no tiene que usar la -Eopción cada vez.
Si le resulta más cómodo de usar egrep, puede hacerlo . Sin embargo, tenga en cuenta que está oficialmente obsoleto. Todavía está presente en todas las distribuciones que verificamos, pero podría desaparecer en el futuro.
Por supuesto, siempre puede crear sus propios alias, por lo que sus opciones favoritas siempre están incluidas para usted.
Desde pequeños comienzos
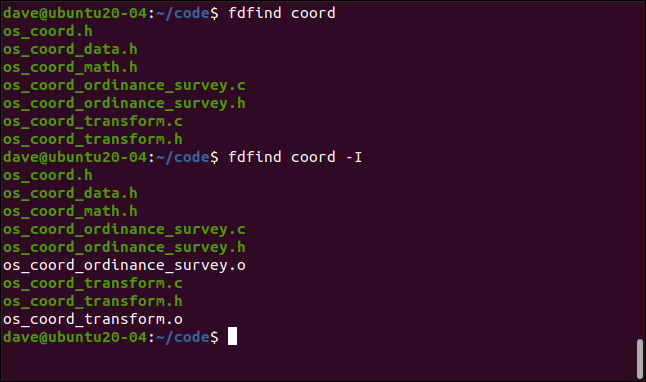
Para nuestros ejemplos, usaremos un archivo de texto sin formato que contiene una lista de Geeks. Recuerde que puede usar expresiones regulares con muchos comandos de Linux. Solo lo estamos usando grep como una forma conveniente de demostrarlos.
Aquí está el contenido del archivo:
menos geek.txt
Se muestra la primera parte del archivo.

Comencemos con un patrón de búsqueda simple y busquemos en el archivo apariciones de la letra «o». Nuevamente, debido a que estamos usando la -Eopción (expresión regular extendida) en todos nuestros ejemplos, escribimos lo siguiente:
grep -E 'o' geeks.txt
Se muestra cada línea que contiene el patrón de búsqueda y se resalta la letra correspondiente. Hemos realizado una búsqueda simple, sin restricciones. No importa si la letra aparece más de una vez, al final de la cadena, dos veces en la misma palabra o incluso al lado de sí misma.
Un par de nombres tenían dobles O; escribimos lo siguiente para enumerar solo aquellos:
grep -E 'oo' geeks.txt
Nuestro conjunto de resultados, como se esperaba, es mucho más pequeño y nuestro término de búsqueda se interpreta literalmente. No significa nada más que lo que escribimos: caracteres dobles «o».
Veremos más funcionalidad con nuestros patrones de búsqueda a medida que avancemos.
Números de línea y otros trucos grep
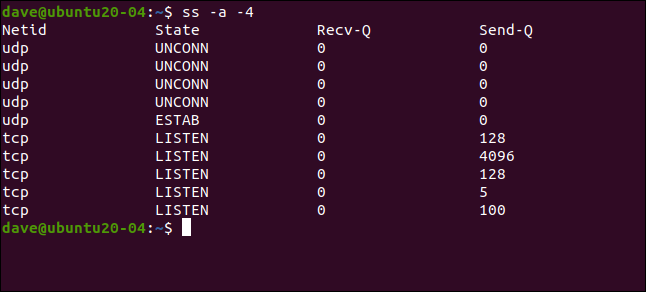
Si desea grep enumerar el número de línea de las entradas coincidentes, puede utilizar la -nopción (número de línea). Esto es un greptruco, no es parte de la funcionalidad de expresiones regulares. Sin embargo, a veces, es posible que desee saber en qué lugar de un archivo se encuentran las entradas coincidentes.
Escribimos lo siguiente:
grep -E -n 'o' geeks.txt

Otro greptruco útil que puede utilizar es la -oopción (única coincidencia). Solo muestra la secuencia de caracteres coincidentes, no el texto circundante. Esto puede resultar útil si necesita escanear rápidamente una lista en busca de coincidencias duplicadas en cualquiera de las líneas.
Para hacerlo, escribimos lo siguiente:
grep -E -n -o 'o' geeks.txt
Si desea reducir la salida al mínimo, puede usar la -copción (contar).
Escribimos lo siguiente para ver el número de líneas en el archivo que contienen coincidencias:
grep -E -c 'o' geeks.txt

El operador de alternancia
Si desea buscar apariciones de doble «l» y doble «o», puede usar el carácter de barra vertical ( |), que es el operador de alternancia. Busca coincidencias para el patrón de búsqueda a su izquierda o derecha.
Escribimos lo siguiente:
grep -E -n -o 'll | oo' geeks.txt
Cualquier línea que contenga una doble «l», «o» o ambas, aparece en los resultados.
Sensibilidad de mayúsculas y minúsculas
También puede utilizar el operador de alternancia para crear patrones de búsqueda, como este:
soy | soy
Esto coincidirá con «am» y «am». Para cualquier cosa que no sean ejemplos triviales, esto conduce rápidamente a patrones de búsqueda engorrosos. Una manera fácil de evitar esto es usar el -i(ignorar el caso) con la opción grep.
Para hacerlo, escribimos lo siguiente:
grep -E 'am' geeks.txt
grep -E -i 'soy' geeks.txt
El primer comando produce tres resultados con tres coincidencias resaltadas. El segundo comando produce cuatro resultados porque la «Am» en «Amanda» también coincide.
Fondeo
También podemos hacer coincidir la secuencia «Am» de otras formas. Por ejemplo, podemos buscar ese patrón específicamente o ignorar el caso y especificar que la secuencia debe aparecer al principio de una línea.
Cuando hace coincidir secuencias que aparecen en la parte específica de una línea de caracteres o una palabra, se denomina anclaje. Utiliza el ^símbolo de intercalación ( ) para indicar que el patrón de búsqueda solo debe considerar una secuencia de caracteres como una coincidencia si aparece al comienzo de una línea.
Escribimos lo siguiente (tenga en cuenta que el signo de intercalación está dentro de las comillas simples):
grep -E ‘Am’ geeks.txt
grep -E -i '^ am' geeks.txt

Ambos comandos coinciden con «Am».
Ahora, busquemos líneas que contengan una «n» doble al final de una línea.
Escribimos lo siguiente, usando un signo de dólar ( $) para representar el final de la línea:
grep -E -i 'nn' geeks.txt
grep -E -i 'nn $' geeks.txt
Comodines
Puede utilizar un punto ( .) para representar cualquier carácter.
Escribimos lo siguiente para buscar patrones que comiencen con «T», terminen con «m» y tengan un solo carácter entre ellos:
grep -E 'Tm' geeks.txt
El patrón de búsqueda coincidió con las secuencias «Tim» y «Tom». También puede repetir los puntos para indicar un cierto número de caracteres.
Escribimos lo siguiente para indicar que no nos importa cuáles son los tres caracteres del medio:
grep-E 'J ... n' geeks.txt
La línea que contiene «Jason» coincide y se muestra.
Use el asterisco ( *) para hacer coincidir cero o más ocurrencias del carácter anterior. En este ejemplo, el carácter que precederá al asterisco es el punto ( .), que (de nuevo) significa cualquier carácter.
Esto significa que el asterisco ( *) coincidirá con cualquier número (incluido el cero) de ocurrencias de cualquier carácter.
El asterisco a veces es confuso para los recién llegados de expresiones regulares. Esto se debe, quizás, a que generalmente lo usan como comodín que significa «cualquier cosa».
Sin embargo, en las expresiones regulares 'c*t' no coincide con «gato», «cuna», «focha», etc. Más bien, se traduce como «coincide con cero o más caracteres ‘c’, seguidos de una ‘t'». Por lo tanto, coincide con «t», «ct», «cct», «ccct» o cualquier número de caracteres «c».
Como conocemos el formato del contenido de nuestro archivo, podemos agregar un espacio como último carácter en el patrón de búsqueda. Solo aparece un espacio en nuestro archivo entre el nombre y los apellidos.
Entonces, escribimos lo siguiente para forzar la búsqueda a incluir solo los primeros nombres del archivo:
grep -E 'J. * n' geeks.txt
grep -E 'J. * n' geeks.txt
A primera vista, los resultados del primer comando parecen incluir algunas coincidencias extrañas. Sin embargo, todos coinciden con las reglas del patrón de búsqueda que usamos.
La secuencia debe comenzar con una «J» mayúscula, seguida de cualquier número de caracteres y luego una «n». Aún así, aunque todas las coincidencias comienzan con «J» y terminan con una «n», algunas de ellas no son lo que cabría esperar.
Debido a que agregamos el espacio en el segundo patrón de búsqueda, obtuvimos lo que pretendíamos: todos los nombres que comienzan con «J» y terminan en «n».
Clases de personajes
Digamos que queremos encontrar todas las líneas que comienzan con una «N» mayúscula o una «W».
Si usamos el siguiente comando, coincidirá con cualquier línea con una secuencia que comience con una «N» o «W» mayúscula, sin importar dónde aparezca en la línea:
grep -E 'N | W' geeks.txt
Eso no es lo que queremos. Si aplicamos el inicio de la línea anchor ( ^) al comienzo del patrón de búsqueda, como se muestra a continuación, obtenemos el mismo conjunto de resultados, pero por una razón diferente:
grep -E '^ N | W' geeks.txt
La búsqueda coincide con las líneas que contienen una «W» mayúscula, en cualquier parte de la línea. También coincide con la línea «No más» porque comienza con una «N» mayúscula. El ancla de inicio de línea ( ^) solo se aplica a la «N» mayúscula
También podríamos agregar un ancla de inicio de línea a la «W» mayúscula, pero eso pronto se volvería ineficiente en un patrón de búsqueda más complicado que nuestro simple ejemplo.
La solución es encerrar parte de nuestro patrón de búsqueda entre corchetes ( []) y aplicar el operador de anclaje al grupo. Los corchetes ( []) significan «cualquier carácter de esta lista». Esto significa que podemos omitir el |operador de alternancia ( ) porque no lo necesitamos.
Podemos aplicar el ancla de inicio de línea a todos los elementos de la lista dentro de los corchetes ( []). (Tenga en cuenta que el inicio del anclaje de línea está fuera de los corchetes).
Escribimos lo siguiente para buscar cualquier línea que comience con una «N» o «W» mayúscula:
grep -E '^ [NW]' geeks.txt
![El comando grep -E '^ [NW]' geeks.txt "en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/x30.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.YIr0nM2bZg.png)
También usaremos estos conceptos en el siguiente conjunto de comandos.
Escribimos lo siguiente para buscar a alguien llamado Tom o Tim:
grep -E 'T [oi] m' geeks.txt
Si el signo de intercalación ( ^) es el primer carácter entre corchetes ( []), el patrón de búsqueda busca cualquier carácter que no aparezca en la lista.
Por ejemplo, escribimos lo siguiente para buscar cualquier nombre que comience con «T», termine en «m» y en el que la letra del medio no sea «o»:
grep -E 'T [^ o] m' geeks.txt
Podemos incluir cualquier número de caracteres en la lista. Escribimos lo siguiente para buscar nombres que comiencen con «T», terminen en «m» y contengan cualquier vocal en el medio:
grep -E 'T [aeiou] m' geeks.txt
![Los comandos "grep -E 'T [oi] m' geeks.txt" y "grep -E 'T [aeiou] m' geeks.txt" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/16.png)
Expresiones de intervalo
Puede usar expresiones de intervalo para especificar el número de veces que desea que el carácter o grupo anterior se encuentre en la cadena coincidente. Encierra el número entre corchetes ( {}).
Un número por sí solo significa específicamente ese número, pero si lo sigue con una coma ( ,), significa ese número o más. Si separa dos números con una coma ( 1,2), significa el rango de números del menor al mayor.
Queremos buscar nombres que comiencen con «T», vayan seguidos de al menos una, pero no más de dos, vocales consecutivas y terminen en «m».
Entonces, escribimos este comando:
grep -E 'T [aeiou] {1,2} m' geeks.txt![El comando "grep -E 'T [aeiou] {1,2} m' geeks.txt" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/17.png)
Esto coincide con «Tim», «Tom» y «Equipo».
Si queremos buscar la secuencia «el», escribimos esto:
grep -E 'el' geeks.txt
Agregamos una segunda «l» al patrón de búsqueda para incluir solo secuencias que contienen doble «l»:
grep -E 'ell' geeks.txt
Esto es equivalente a este comando:
grep -E 'el {2}' geeks.txtSi proporcionamos un rango de «al menos una y no más de dos» apariciones de «l», coincidirá con las secuencias «el» y «ell».
Esto es sutilmente diferente de los resultados del primero de estos cuatro comandos, en el que todas las coincidencias fueron para las secuencias «el», incluidas las que están dentro de las secuencias «ell» (y solo una «l» está resaltada).
Escribimos lo siguiente:
grep -E 'el {1,2}' geeks.txt
Para encontrar todas las secuencias de dos o más vocales, escribimos este comando:
grep -E '[aeiou] {2,}' geeks.txt![El comando "grep -E '[aeiou] {2,}' geeks.txt" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/23.png)
Personajes que escapan
Digamos que queremos encontrar líneas en las que un punto ( .) es el último carácter. Sabemos que el signo de dólar ( $) es el final del ancla de línea, por lo que podríamos escribir esto:
grep -E '. $' geeks.txt

Sin embargo, como se muestra a continuación, no obtenemos lo que esperábamos.
Como vimos anteriormente, el punto ( .) coincide con cualquier carácter. Debido a que cada línea termina con un carácter, cada línea se devolvió en los resultados.
Entonces, ¿cómo evita que un carácter especial realice su función de expresión regular cuando solo desea buscar ese carácter real? Para hacer esto, usa una barra invertida ( \) para escapar del carácter.
Una de las razones por las que estamos usando las -Eopciones (extendidas) es porque requieren mucho menos escape cuando usa las expresiones regulares básicas.
Escribimos lo siguiente:
grep -e '\. $' geeks.txt
Esto coincide con el carácter de punto real ( .) al final de una línea.
Anclaje y palabras
Cubrimos los anclajes de inicio ( ^) y final de línea ( $) arriba. Sin embargo, puede utilizar otros anclajes para operar en los límites de las palabras.
En este contexto, una palabra es una secuencia de caracteres delimitada por espacios en blanco (el comienzo o el final de una línea). Entonces, «psy66oh» contaría como una palabra, aunque no la encontrarás en un diccionario.
El comienzo del ancla de la palabra es ( \<); observe que apunta a la izquierda, al comienzo de la palabra. Digamos que un nombre se escribió por error en minúsculas. Podemos usar la -iopción grep para realizar una búsqueda que no distinga entre mayúsculas y minúsculas y encontrar nombres que comiencen con «h».
Escribimos lo siguiente:
grep -E -i 'h' geeks.txt
Eso encuentra todas las apariciones de «h», no solo aquellas al comienzo de las palabras.
grep -E -i '\ <h' geeks.txt
Esto solo encuentra aquellos al comienzo de las palabras.
Hagamos algo similar con la letra “y”; solo queremos ver casos en los que esté al final de una palabra. Escribimos lo siguiente:
grep -E 'y' geeks.txt
Esto busca todas las apariciones de «y», dondequiera que aparezca en las palabras.
Ahora, escribimos lo siguiente, usando el final de la palabra anchor ( />) (que apunta a la derecha o al final de la palabra):
grep -E 'y \>' geeks.txt
El segundo comando produce el resultado deseado.
Para crear un patrón de búsqueda que busque una palabra completa, puede usar el operador de límite ( \b). Usaremos el operador de límite ( \B) en ambos extremos del patrón de búsqueda para encontrar una secuencia de caracteres que debe estar dentro de una palabra más grande:
grep -E '\ bGlenn \ b' geeks.txt
grep -E '\ Bway \ B' geeks.txt
Más clases de personajes
Puede utilizar atajos para especificar las listas en clases de caracteres. Estos indicadores de rango le ahorran tener que escribir cada miembro de una lista en el patrón de búsqueda.
Puede utilizar todo lo siguiente:
- AZ: todas las letras mayúsculas de la «A» a la «Z».
- az: todas las letras minúsculas de la «a» a la «z».
- 0-9: Todos los dígitos del cero al nueve.
- dp: todas las letras minúsculas de la «d» a la «p». Estos estilos de formato libre le permiten definir su propio rango.
- 2-7: Todos los números del dos al siete.
También puede utilizar tantas clases de caracteres como desee en un patrón de búsqueda. El siguiente patrón de búsqueda coincide con secuencias que comienzan con «J», seguidas de una «o» o «s», y luego una «e», «h», «l» o «s»:
grep -E 'J [os] [ehls]' geeks.txt
![El comando "grep -E 'J [os] [ehls]' geeks.txt" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/31.png)
En nuestro próximo comando, usaremos el a-zespecificador de rango.
Nuestro comando de búsqueda se descompone de esta manera:
- H: la secuencia debe comenzar con «H.»
- [az]: el siguiente carácter puede ser cualquier letra minúscula de este rango.
- *: El asterisco aquí representa cualquier número de letras minúsculas.
- man: la secuencia debe terminar con «man».
Lo ponemos todo junto en el siguiente comando:
grep -E 'H [az] * man' geeks.txt
![El comando "grep -E 'H [az] * man' geeks.txt" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/32.png)
Nada es impenetrable
Algunas expresiones regulares pueden volverse rápidamente difíciles de analizar visualmente. Cuando las personas escriben expresiones regulares complicadas, generalmente comienzan pequeñas y agregan más y más secciones hasta que funciona. Tienden a aumentar su sofisticación con el tiempo.
Cuando intentas trabajar hacia atrás desde la versión final para ver qué hace, es un desafío completamente diferente.
Por ejemplo, mire este comando:
grep -E '^ ([0-9] {4} [-]) {3} [0-9] {4} | [0-9] {16}' geeks.txt¿Por dónde empezarías a desenredar esto? Comenzaremos por el principio y lo tomaremos un fragmento a la vez:
- ^: El inicio del ancla de línea. Entonces, nuestra secuencia tiene que ser lo primero en una línea.
- ([0-9] {4} [-]): los paréntesis reúnen los elementos del patrón de búsqueda en un grupo. Se pueden aplicar otras operaciones a este grupo en su conjunto (más sobre esto más adelante). El primer elemento es una clase de caracteres que contiene un rango de dígitos de cero a nueve
[0-9]. Nuestro primer carácter, entonces, es un dígito del cero al nueve. A continuación, tenemos una expresión de intervalo que contiene el número cuatro{4}. Esto se aplica a nuestro primer carácter, que sabemos que será un dígito. Por lo tanto, la primera parte del patrón de búsqueda ahora tiene cuatro dígitos. Puede ir seguido de un espacio o un guión ([- ]) de otra clase de caracteres. - {3}: un especificador de intervalo que contiene el número tres sigue inmediatamente al grupo. Se aplica a todo el grupo, por lo que nuestro patrón de búsqueda ahora es de cuatro dígitos, seguido de un espacio o un guión, que se repite tres veces.
- [0-9]: A continuación, tenemos otra clase de caracteres que contiene un rango de dígitos de cero a nueve
[0-9]. Esto agrega otro carácter al patrón de búsqueda, y puede ser cualquier dígito del cero al nueve. - {4}: otra expresión de intervalo que contiene el número cuatro se aplica al carácter anterior. Esto significa que el carácter se convierte en cuatro caracteres, todos los cuales pueden ser cualquier dígito del cero al nueve.
- |: El operador de alternancia nos dice que todo lo que está a la izquierda es un patrón de búsqueda completo y que todo lo que está a la derecha es un nuevo patrón de búsqueda. Por lo tanto, este comando está buscando uno de dos patrones de búsqueda. El primero son tres grupos de cuatro dígitos, seguidos de un espacio o un guión, y luego otros cuatro dígitos añadidos.
- [0-9]: El segundo patrón de búsqueda comienza con cualquier dígito del cero al nueve.
- {16}: se aplica un operador de intervalo al primer carácter y lo convierte en 16 caracteres, todos los cuales son dígitos.
Entonces, nuestro patrón de búsqueda buscará cualquiera de los siguientes:
- Cuatro grupos de cuatro dígitos, con cada grupo separado por un espacio o un guión (
-). - Un grupo de dieciséis dígitos.
Los resultados se muestran a continuación.
![El comando "grep -E '^ ([0-9] {4} [-]) {3} [0-9] {4} | [0-9] {16}' geeks.txt" en una ventana de terminal .](https://respontodo.com/wp-content/uploads/2020/10/36.png)
Este patrón de búsqueda busca formas comunes de escribir números de tarjetas de crédito. También es lo suficientemente versátil como para encontrar diferentes estilos, con un solo comando.
Tomar con calma
La complejidad suele ser simplemente mucha simplicidad unida. Una vez que comprenda los bloques de construcción fundamentales, puede crear utilidades potentes y eficientes y desarrollar nuevas habilidades valiosas.