Tabla de contenidos
Puede parecer una locura, pero el sedcomando de Linux es un editor de texto sin interfaz. Puede usarlo desde la línea de comandos para manipular texto en archivos y transmisiones. Le mostraremos cómo aprovechar su poder.
El poder de sed
El sedcomando es un poco como el ajedrez: se necesita una hora para aprender los conceptos básicos y una vida para dominarlos (o, al menos, mucha práctica). Le mostraremos una selección de tácticas de apertura en cada una de las principales categorías de sedfuncionalidad.
sedes un editor de flujo que funciona con entradas canalizadas o archivos de texto. Sin embargo, no tiene una interfaz de editor de texto interactivo. Más bien, le proporciona instrucciones para que las siga a medida que avanza en el texto. Todo esto funciona en Bash y otros shells de línea de comandos.
Con sedpuede hacer todo lo siguiente:
- Seleccionar texto
- Sustituir texto
- Agregar líneas al texto
- Eliminar líneas del texto
- Modificar (o conservar) un archivo original
Hemos estructurado nuestros ejemplos para presentar y demostrar conceptos, no para producir los comandos más tersos (y menos accesibles) sed. Sin embargo, las funcionalidades de selección de texto y coincidencia de patrones sed dependen en gran medida de las expresiones regulares ( expresiones regulares ). Necesitará familiarizarse con estos para aprovecharlos al máximo sed.
Un ejemplo simple
Primero, usaremos echopara enviar un texto a sed través de una tubería y sed sustituiremos una parte del texto. Para hacerlo, escribimos lo siguiente:
echo howtogonk | sed 's / gonk / geek /'
El echocomando envía «howtogonk» sedy se aplica nuestra regla de sustitución simple (la «s» significa sustitución). sed busca en el texto de entrada una ocurrencia de la primera cadena y reemplazará cualquier coincidencia con la segunda.
La cadena «gonk» se reemplaza por «geek» y la nueva cadena se imprime en la ventana del terminal.

Las sustituciones son probablemente el uso más común de sed. Sin embargo, antes de que podamos profundizar en las sustituciones, necesitamos saber cómo seleccionar y combinar texto.
Seleccionar texto
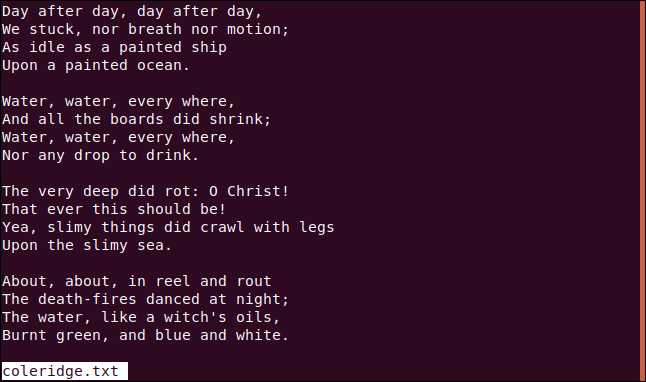
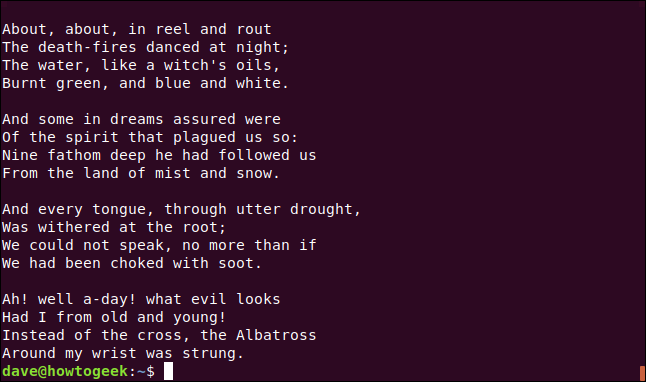
Necesitaremos un archivo de texto para nuestros ejemplos. Usaremos uno que contiene una selección de versos del poema épico de Samuel Taylor Coleridge «The Rime of the Ancient Mariner».
Escribimos lo siguiente para echarle un vistazo con less:
menos coleridge.txt
Para seleccionar algunas líneas del archivo, proporcionamos las líneas inicial y final del rango que queremos seleccionar. Un solo número selecciona esa línea.
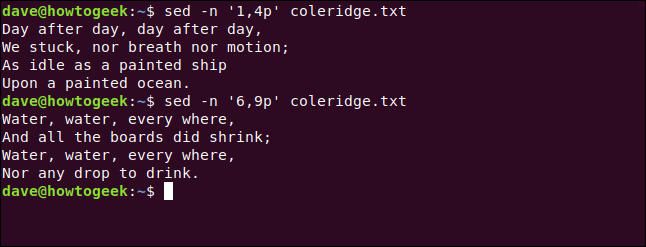
Para extraer las líneas uno a cuatro, escribimos este comando:
sed -n '1,4p' coleridge.txt
Tenga en cuenta la coma entre 1y 4. Los pmedios de “imprimir líneas emparejados.” De forma predeterminada, sed imprime todas las líneas. Veríamos todo el texto en el archivo con las líneas coincidentes impresas dos veces. Para evitar esto, usaremos la -nopción (silencioso) para suprimir el texto no coincidente.
Cambiamos los números de línea para que podamos seleccionar un verso diferente, como se muestra a continuación:
sed -n '6,9p' coleridge.txt
Podemos usar la -eopción (expresión) para realizar selecciones múltiples. Con dos expresiones, podemos seleccionar dos versos, así:
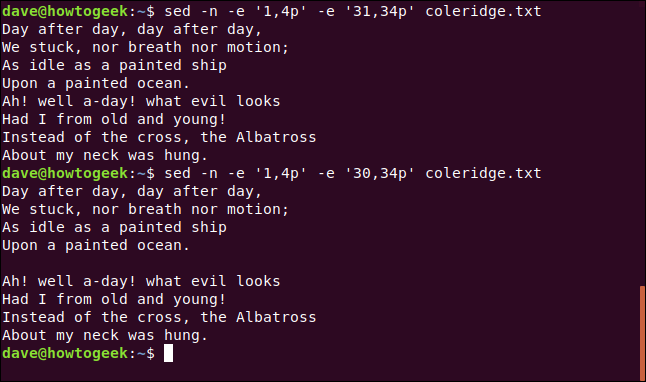
sed -n -e '1,4p' -e '31, 34p 'coleridge.txt
Si reducimos el primer número en la segunda expresión, podemos insertar un espacio en blanco entre los dos versos. Escribimos lo siguiente:
sed -n -e '1,4p' -e '30, 34p 'coleridge.txt
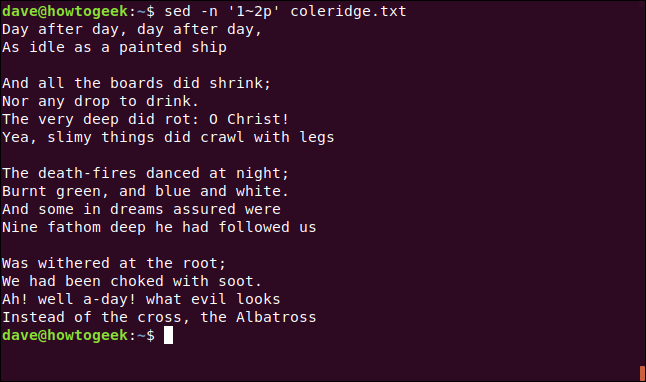
También podemos elegir una línea de inicio y decirle sed que recorra el archivo e imprima líneas alternas, cada quinta línea, o que salte cualquier número de líneas. El comando es similar a los que usamos anteriormente para seleccionar un rango. Esta vez, sin embargo, usaremos una tilde ( ~) en lugar de una coma para separar los números.
El primer número indica la línea de partida. El segundo número indica sedqué líneas después de la línea de inicio queremos ver. El número 2 significa cada segunda línea, 3 significa cada tercera línea, y así sucesivamente.
Escribimos lo siguiente:
sed -n '1 ~ 2p' coleridge.txt
No siempre sabrá dónde se encuentra el texto que está buscando en el archivo, lo que significa que los números de línea no siempre serán de mucha ayuda. Sin embargo, también puede utilizar sed para seleccionar líneas que contienen patrones de texto coincidentes. Por ejemplo, extraigamos todas las líneas que comiencen con «Y».
El signo de intercalación ( ^) representa el inicio de la línea. Incluiremos nuestro término de búsqueda entre barras diagonales ( /). También incluimos un espacio después de «Y» para que palabras como «Android» no se incluyan en el resultado.
Leer sedguiones puede ser un poco difícil al principio. La /p “impresión” medios tal como lo hizo en los comandos que hemos utilizado anteriormente. Sin embargo, en el siguiente comando, una barra diagonal lo precede:
sed -n '/ ^ Y / p' coleridge.txt
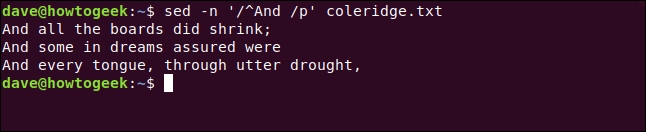
Tres líneas que comienzan con «Y» se extraen del archivo y se muestran para nosotros.
Haciendo sustituciones
En nuestro primer ejemplo, le mostramos el siguiente formato básico para una sedsustitución:
echo howtogonk | sed 's / gonk / geek /'
El sdice que sed esto es una sustitución. La primera cadena es el patrón de búsqueda y la segunda es el texto con el que queremos reemplazar ese texto coincidente. Por supuesto, como con todas las cosas de Linux, el diablo está en los detalles.
Escribimos lo siguiente para cambiar todas las apariciones de «día» a «semana» y darle al marinero y al albatros más tiempo para vincularse:
sed -n 's / día / semana / p' coleridge.txt
En la primera línea, solo se cambia la segunda aparición de «día». Esto se debe a que se seddetiene después de la primera coincidencia por línea. Tenemos que agregar una «g» al final de la expresión, como se muestra a continuación, para realizar una búsqueda global de modo que se procesen todas las coincidencias en cada línea:
sed -n 's / día / semana / gp' coleridge.txt
Esto coincide con tres de los cuatro de la primera línea. Dado que la primera palabra es «Día» y seddistingue entre mayúsculas y minúsculas, no considera que esa instancia sea la misma que «día».
Escribimos lo siguiente, agregando un i al comando al final de la expresión para indicar que no se distingue entre mayúsculas y minúsculas:
sed -n 's / día / semana / gip' coleridge.txt
Esto funciona, pero es posible que no siempre desee activar la insensibilidad a mayúsculas y minúsculas para todo. En esos casos, puede usar un grupo de expresiones regulares para agregar insensibilidad a mayúsculas y minúsculas específicas del patrón.
Por ejemplo, si incluimos caracteres entre corchetes ( []), se interpretan como «cualquier carácter de esta lista de caracteres».
Escribimos lo siguiente e incluimos «D» y «d» en el grupo, para asegurarnos de que coincida con «Día» y «día»:
sed -n 's / [Dd] ay / week / gp' coleridge.txt
![El "sed -n 's / day / week / p' coleridge.txt", "sed -n 's / day / week / gp' coleridge.txt", "sed -n 's / day / week / gip' coleridge.txt "y" sed -n 's / [Dd] ay / week / gp' coleridge.txt "en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/x16.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.IZvoVbRvNb.png)
También podemos restringir las sustituciones a secciones del archivo. Digamos que nuestro archivo contiene un espaciado extraño en el primer verso. Podemos usar el siguiente comando familiar para ver el primer versículo:
sed -n '1,4p' coleridge.txt
Buscaremos dos espacios y los sustituiremos por uno. Haremos esto globalmente para que la acción se repita en toda la línea. Para ser claros, el patrón de búsqueda es espacio, espacio asterisco ( *) y la cadena de sustitución es un solo espacio. La 1,4restringe la sustitución de las cuatro primeras líneas del archivo.
Ponemos todo eso junto en el siguiente comando:
sed -n '1,4 s / * / / gp' coleridge.txt
¡Esto funciona muy bien! El patrón de búsqueda es lo importante aquí. El asterisco ( *) representa cero o más del carácter anterior, que es un espacio. Por lo tanto, el patrón de búsqueda busca cadenas de un espacio o más.
Si sustituimos un solo espacio por cualquier secuencia de múltiples espacios, regresaremos el archivo al espaciado regular, con un solo espacio entre cada palabra. Esto también sustituirá un solo espacio por un solo espacio en algunos casos, pero esto no afectará nada adversamente; aún obtendremos el resultado deseado.
Si escribimos lo siguiente y reducimos el patrón de búsqueda a un solo espacio, verá inmediatamente por qué tenemos que incluir dos espacios:
sed -n '1,4 s / * / / gp' coleridge.txt
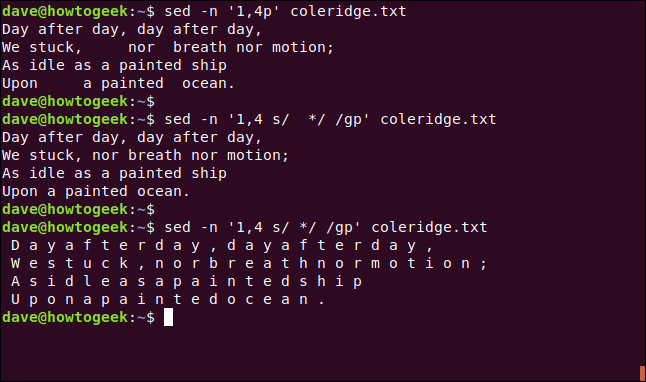
Debido a que el asterisco coincide con cero o más del carácter anterior, ve cada carácter que no es un espacio como un «espacio cero» y le aplica la sustitución.
Sin embargo, si incluimos dos espacios en el patrón de búsqueda, seddebemos encontrar al menos un carácter de espacio antes de que se aplique la sustitución. Esto asegura que los caracteres no espaciales permanecerán intactos.
Escribimos lo siguiente, usando la -e(expresión) que usamos anteriormente, que nos permite hacer dos o más sustituciones simultáneamente:
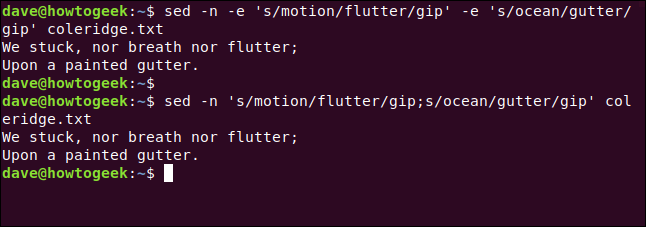
sed -n -e 's / motion / flutter / gip' -e 's / ocean / gutter / gip' coleridge.txt
Podemos lograr el mismo resultado si usamos un punto y coma ( ;) para separar las dos expresiones, así:
sed -n 's / motion / flutter / gip; s / ocean / gutter / gip' coleridge.txt
Cuando cambiamos «día» por «semana» en el siguiente comando, la instancia de «día» en la expresión «bien al día» también se cambió:
sed -n 's / [Dd] ay / week / gp' coleridge.txt
Para evitar esto, solo podemos intentar sustituciones en líneas que coincidan con otro patrón. Si modificamos el comando para tener un patrón de búsqueda al principio, solo consideraremos operar en líneas que coincidan con ese patrón.
Escribimos lo siguiente para que nuestro patrón coincidente sea la palabra «después»:
sed -n '/ after / s / [Dd] ay / week / gp' coleridge.txt
Eso nos da la respuesta que queremos.
![Los comandos "sed -n 's / [Dd] ay / week / gp' coleridge.txt" y "sed -n '/ after / s / [Dd] ay / week / gp' coleridge.txt" en una ventana de terminal .](https://respontodo.com/wp-content/uploads/2020/10/x20.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.55qpFqyIPC.png)
Sustituciones más complejas
Demos un descanso a Coleridge y utilizamos sedpara extraer nombres del etc/passwdarchivo.
Hay formas más cortas de hacer esto (más sobre eso más adelante), pero usaremos la forma más larga aquí para demostrar otro concepto. Cada elemento coincidente en un patrón de búsqueda (llamado subexpresiones) se puede numerar (hasta un máximo de nueve elementos). Luego puede usar estos números en sus sedcomandos para hacer referencia a subexpresiones específicas.
Debe encerrar la subexpresión entre paréntesis [ ()] para que esto funcione. Los paréntesis también deben ir precedidos de una barra inclinada hacia atrás ( \) para evitar que sean tratados como un carácter normal.
Para hacer esto, debe escribir lo siguiente:
sed 's / \ ([^:] * \). * / \ 1 /' / etc / passwd
![sed 's / \ ([^:] * \). * / \ 1 /' / etc / passwd en una ventana de terminal](https://respontodo.com/wp-content/uploads/2020/10/x12-1.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.rD2VWvR5oz.png)
Analicemos esto:
sed 's/: Elsedcomando y el comienzo de la expresión de sustitución.\(: El paréntesis de apertura [(] que encierra la subexpresión, precedido por una barra invertida (\).[^:]*: La primera subexpresión del término de búsqueda contiene un grupo entre corchetes. El signo de intercalación (^) significa «no» cuando se usa en un grupo. Un grupo significa que cualquier carácter que no sea dos puntos (:) será aceptado como coincidencia.\): El paréntesis de cierre [)] con una barra diagonal inversa (\)..*: Esta segunda subexpresión de búsqueda significa «cualquier carácter y cualquier número de ellos»./\1: La parte de sustitución de la expresión contiene1precedida por una barra invertida (\). Esto representa el texto que coincide con la primera subexpresión./': La barra oblicua de cierre (/) y la comilla simple (') terminan elsedcomando.
Lo que todo esto significa es que buscaremos cualquier cadena de caracteres que no contenga dos puntos ( :), que será la primera instancia de texto coincidente. Luego, buscamos cualquier otra cosa en esa línea, que será la segunda instancia de texto coincidente. Vamos a sustituir toda la línea por el texto que coincidió con la primera subexpresión.
Cada línea del /etc/passwdarchivo comienza con un nombre de usuario terminado en dos puntos. Emparejamos todo hasta los primeros dos puntos y luego sustituimos ese valor por toda la línea. Entonces, hemos aislado los nombres de usuario.
A continuación, encerraremos la segunda subexpresión entre paréntesis [ ()] para que también podamos hacer referencia a ella por número. También reemplazaremos \1 con \2. Nuestro comando ahora sustituirá toda la línea con todo, desde los primeros dos puntos ( :) hasta el final de la línea.
Escribimos lo siguiente:
sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd
![El comando "sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd" en una ventana de terminal.](https://respontodo.com/wp-content/uploads/2020/10/x14-1.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.EoV_aWj-CM.png)
Esos pequeños cambios invierten el significado del comando y obtenemos todo menos los nombres de usuario.
![Salida de sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd en una ventana de terminal](https://respontodo.com/wp-content/uploads/2020/10/x15.pagespeed.gp-jp-jw-pj-ws-js-rj-rp-rw-ri-cp-md.ic_.WBDulzIV26.png)
Ahora, echemos un vistazo a la forma rápida y fácil de hacer esto.
Nuestro término de búsqueda va desde los primeros dos puntos ( :) hasta el final de la línea. Debido a que nuestra expresión de sustitución está vacía ( //), no reemplazaremos el texto coincidente con nada.
Entonces, escribimos lo siguiente, cortando todo, desde los primeros dos puntos ( :) hasta el final de la línea, dejando solo los nombres de usuario:
sed 's /:.*// "/ etc / passwd

Veamos un ejemplo en el que hacemos referencia a la primera y la segunda coincidencia en el mismo comando.
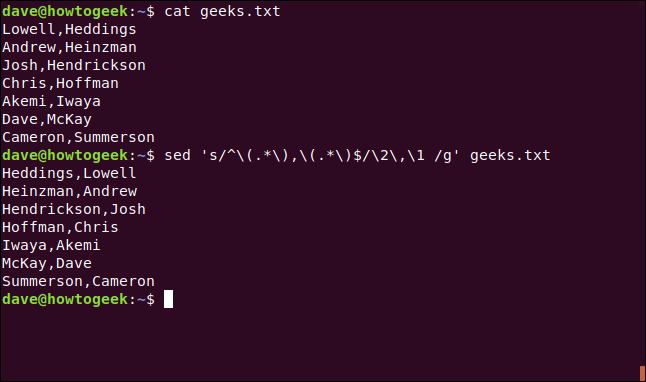
Tenemos un archivo de comas ( ,) que separa nombres y apellidos. Queremos incluirlos como «apellido, nombre». Podemos usar cat, como se muestra a continuación, para ver qué hay en el archivo:
gato geeks.txt
Como muchos sedcomandos, el siguiente puede parecer impenetrable al principio:
sed 's / ^ \ (. * \), \ (. * \) $ / \ 2, \ 1 / g' geeks.txt
Este es un comando de sustitución como los otros que hemos usado, y el patrón de búsqueda es bastante fácil. Lo desglosaremos a continuación:
sed 's/: El comando de sustitución normal.^: Debido a que el símbolo de intercalación no está en un grupo ([]), significa «El comienzo de la línea».\(.*\),: La primera subexpresión es cualquier número de caracteres. Está encerrado entre paréntesis [()], cada uno de los cuales está precedido por una barra invertida (\) para que podamos hacer referencia a él por número. Todo nuestro patrón de búsqueda hasta ahora se traduce como una búsqueda desde el principio de la línea hasta la primera coma (,) para cualquier número de caracteres.\(.*\): La siguiente subexpresión es (nuevamente) cualquier número de cualquier carácter. También está entre paréntesis [()], ambos precedidos por una barra invertida (\) para que podamos hacer referencia al texto coincidente por número.$/: El signo de dólar ($) representa el final de la línea y permitirá que nuestra búsqueda continúe hasta el final de la línea. Hemos usado esto simplemente para presentar el signo de dólar. Realmente no lo necesitamos aquí, ya que el asterisco (*) iría al final de la línea en este escenario. La barra inclinada (/) completa la sección del patrón de búsqueda.\2,\1 /g': Como encerramos nuestras dos subexpresiones entre paréntesis, podemos referirnos a ambas por sus números. Como queremos invertir el orden, los escribimos comosecond-match,first-match. Los números deben ir precedidos de una barra invertida (\)./g: Esto permite que nuestro comando funcione globalmente en cada línea.geeks.txt: El archivo en el que estamos trabajando.
También puede utilizar el comando Cortar ( c) para sustituir líneas enteras que coincidan con su patrón de búsqueda. Escribimos lo siguiente para buscar una línea con la palabra «cuello» y la reemplazamos con una nueva cadena de texto:
sed '/ neck / c Alrededor de mi muñeca estaba colgado' coleridge.txt

Nuestra nueva línea aparece ahora al final de nuestro extracto.
Insertar líneas y texto
También podemos insertar nuevas líneas y texto en nuestro archivo. Para insertar nuevas líneas después de las que coincidan, usaremos el comando Append ( a).
Aquí está el archivo con el que vamos a trabajar:
gato geeks.txt
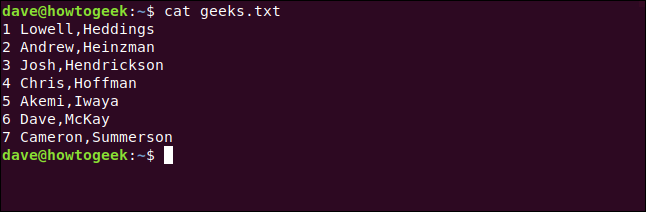
Hemos numerado las líneas para que sea un poco más fácil de seguir.
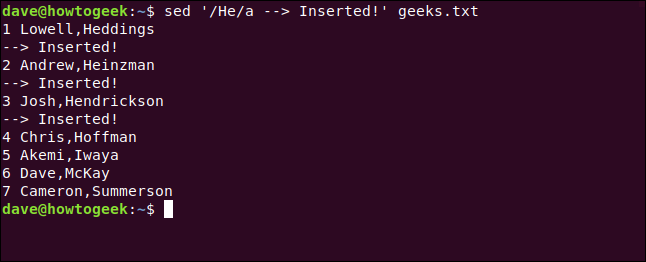
Escribimos lo siguiente para buscar líneas que contengan la palabra «Él» e insertamos una nueva línea debajo de ellas:
sed '/ He / a -> Insertado!' geeks.txt
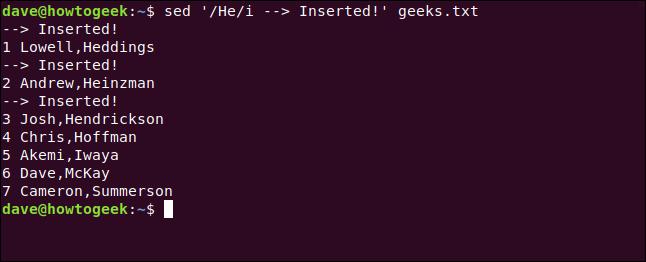
Escribimos lo siguiente e incluimos el comando Insertar ( i) para insertar la nueva línea encima de las que contienen texto coincidente:
sed '/ He / i -> Insertado!' geeks.txt
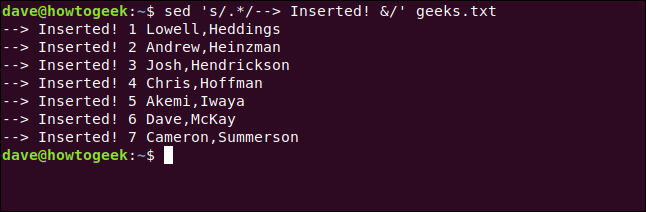
Podemos usar el ampersand ( &), que representa el texto coincidente original, para agregar texto nuevo a una línea coincidente. \1 , \2y así sucesivamente, representan subexpresiones coincidentes.
Para agregar texto al comienzo de una línea, usaremos un comando de sustitución que coincide con todo en la línea, combinado con una cláusula de reemplazo que combina nuestro nuevo texto con la línea original.
Para hacer todo esto, escribimos lo siguiente:
sed 's /.*/--> Insertado & /' geeks.txt
Escribimos lo siguiente, incluido el Gcomando, que agregará una línea en blanco entre cada línea:
sed 'G' geeks.txt
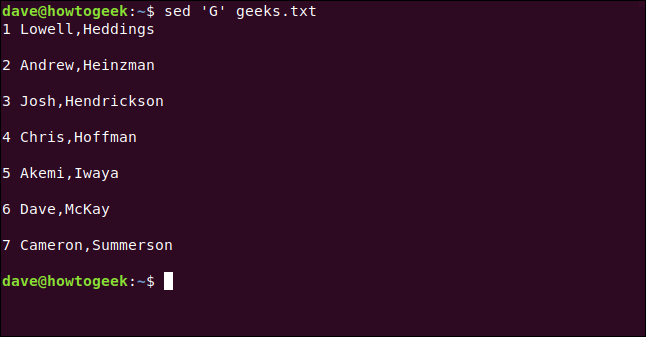
Si desea agregar dos o más líneas en blanco, se puede utilizar G;G, G;G;Gy así sucesivamente.
Eliminar líneas
El comando Eliminar ( d) elimina las líneas que coinciden con un patrón de búsqueda o aquellas especificadas con números de línea o rangos.
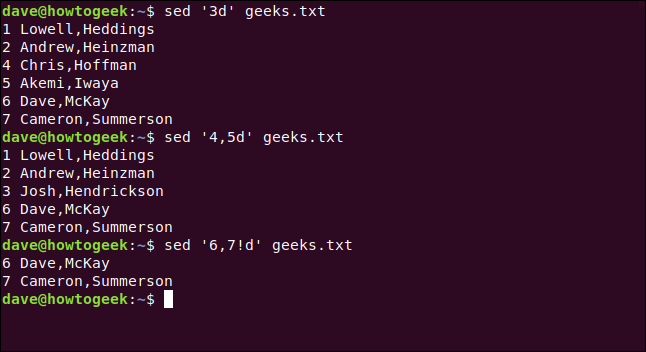
Por ejemplo, para eliminar la tercera línea, escribiríamos lo siguiente:
sed '3d' geeks.txt
Para eliminar el rango de las líneas cuatro a cinco, escribiríamos lo siguiente:
sed '4,5d' geeks.txt
Para eliminar líneas fuera de un rango, usamos un signo de exclamación ( !), como se muestra a continuación:
sed '6,7! d' geeks.txt
Guardar sus cambios
Hasta ahora, todos nuestros resultados se han impreso en la ventana de la terminal, pero aún no los hemos guardado en ninguna parte. Para que estos sean permanentes, puede escribir sus cambios en el archivo original o redirigirlos a uno nuevo.
Sobrescribir su archivo original requiere cierta precaución. Si su sedcomando es incorrecto, puede realizar algunos cambios en el archivo original que son difíciles de deshacer.
Para su tranquilidad, sed puede crear una copia de seguridad del archivo original antes de que ejecute su comando.
Puede usar la opción In-place ( -i) para indicarle sedque escriba los cambios en el archivo original, pero si le agrega una extensión de archivo, sed hará una copia de seguridad del archivo original en uno nuevo. Tendrá el mismo nombre que el archivo original, pero con una nueva extensión de archivo.
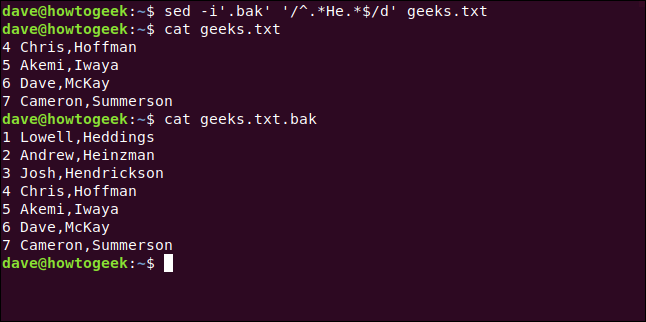
Para demostrarlo, buscaremos las líneas que contengan la palabra «Él» y las borraremos. También haremos una copia de seguridad de nuestro archivo original en uno nuevo usando la extensión BAK.
Para hacer todo esto, escribimos lo siguiente:
sed -i'.bak '' /^.*He.*$/d 'geeks.txt
Escribimos lo siguiente para asegurarnos de que nuestro archivo de respaldo no se modifique:
gato geeks.txt.bak
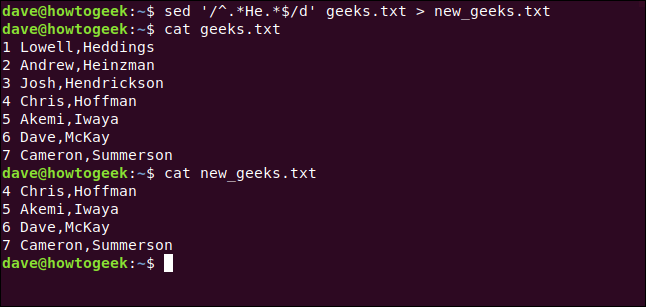
También podemos escribir lo siguiente para redirigir la salida a un nuevo archivo y lograr un resultado similar:
sed -i'.bak '' /^.*He.*$/d 'geeks.txt> new_geeks.txt
Usamos catpara confirmar que los cambios se escribieron en el nuevo archivo, como se muestra a continuación:
gato new_geeks.txt
Habiendo sedido todo eso
Como probablemente haya notado, incluso esta introducción rápida sedes bastante larga. Hay mucho en este comando, y aún puedes hacer más con él .
Sin embargo, con suerte, estos conceptos básicos le han proporcionado una base sólida sobre la que puede construir a medida que continúa aprendiendo más.