Tabla de contenidos

El comando de Linux cutle permite extraer porciones de texto de archivos o flujos de datos. Es especialmente útil para trabajar con datos delimitados, como archivos CSV . Esto es lo que necesita saber.
El comando de corte
El cutcomando es un veterano del mundo Unix y debutó en 1982 como parte de AT&T System III UNIX. Su propósito en la vida es recortar secciones de texto de archivos o secuencias, de acuerdo con los criterios que establezca. Su sintaxis es tan simple como su propósito, pero es esta simplicidad conjunta lo que lo hace tan útil.
Al estilo tradicional de UNIX, al combinarse cutcon otras utilidades comogrep usted, puede crear soluciones elegantes y poderosas para problemas desafiantes. Si bien existen diferentes versiones de cut, vamos a discutir la versión estándar de GNU/Linux. Tenga en cuenta que otras versiones, en particular las cutque se encuentran en las variantes BSD , no incluyen todas las opciones descritas aquí.
Puede verificar qué versión está instalada en su computadora emitiendo este comando:
cortar --versión
Si ve «GNU coreutils» en el resultado, está en la versión que vamos a describir en este artículo. Todas las versiones de cuttienen algo de esta funcionalidad, pero a la versión de Linux se le han agregado mejoras.
Primeros pasos con corte
Ya sea que estemos canalizando informacióncut o usando para cutleer un archivo , los comandos que usamos son los mismos. Cualquier cosa que pueda hacer con un flujo de entrada cutse puede hacer en una línea de texto de un archivo, y viceversa . Podemos decir cuttrabajar con bytes, caracteres o campos delimitados.
Para seleccionar un solo byte, usamos la -bopción (byte) e cutindicamos qué byte o bytes queremos. En este caso, es el byte cinco. Estamos enviando la cadena «cómo hacer geek» al cutcomando con una tubería, «|», desde echo.
echo 'cómo hacer friki' | cortar -b 5

El quinto byte en esa cadena es «t», por lo que cutresponde imprimiendo «t» en la ventana de la terminal.
Para especificar un rango usamos un guión. Para extraer los bytes del 5 al 11 inclusive, emitiríamos este comando:
echo 'cómo hacer friki' | cortar -b 5-11

Puede proporcionar múltiples bytes individuales o rangos separándolos con comas. Para extraer el byte 5 y el byte 11, use este comando:
echo 'cómo hacer friki' | cortar -b 5,11

Para obtener la primera letra de cada palabra podemos usar este comando:
echo 'cómo hacer friki' | cortar -b 1,5,8

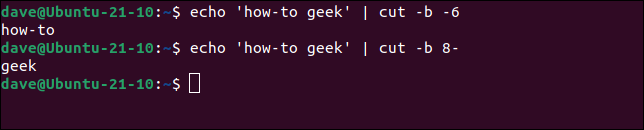
Si usa el guión sin un primer número, cutdevuelve todo desde la posición 1 hasta el número. Si usa el guión sin un segundo número, cutdevuelve todo, desde el primer número hasta el final de la secuencia o línea.
echo 'cómo hacer friki' | cortar -b -6
echo 'cómo hacer friki' | corte -b 8-
Uso de corte con caracteres
Usar cutcon caracteres es más o menos lo mismo que usarlo con bytes. En ambos casos hay que tener especial cuidado con los caracteres complejos. Al usar la -copción (carácter), le indicamos cutque trabaje en términos de caracteres, no de bytes.
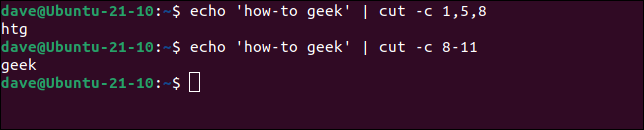
echo 'cómo hacer friki' | cortar -c 1,5,8
echo 'cómo hacer friki' | cortar -c 8-11
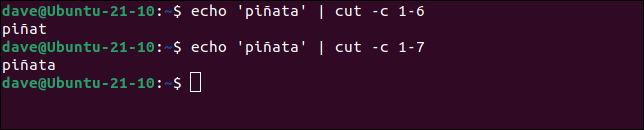
Estos funcionan exactamente como cabría esperar. Pero mira este ejemplo. Es una palabra de seis letras, por lo que solicitar cutque se devuelvan los caracteres del uno al seis debería devolver la palabra completa. Pero no es así. Es un carácter corto. Para ver la palabra completa tenemos que preguntar por los caracteres del uno al siete.
echo 'piñata' | cortar -c 1-6
echo 'piñata' | cortar -c 1-7
El problema es que el carácter «ñ» en realidad está compuesto por dos bytes. Podemos ver esto muy fácilmente. Tenemos un archivo de texto corto que contiene esta línea de texto:
gato unicode.txt

Examinaremos ese archivo con la hexdumputilidad. Usar la -Copción (canónica) nos da una tabla de dígitos hexadecimales con el equivalente ASCII a la derecha. En la tabla ASCII, no se muestra la “ñ”, sino que hay puntos que representan dos caracteres no imprimibles. Estos son los bytes resaltados en la tabla hexadecimal .
volcado hexadecimal -C unicode.txt
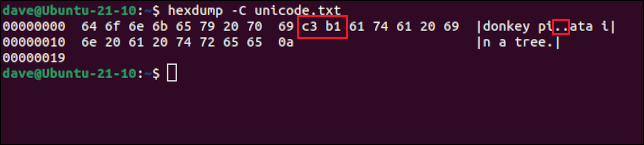
Estos dos bytes son utilizados por el programa de visualización, en este caso, el shell Bash, para identificar la «ñ». Muchos caracteres Unicode usan tres o más bytes para representar un solo carácter.
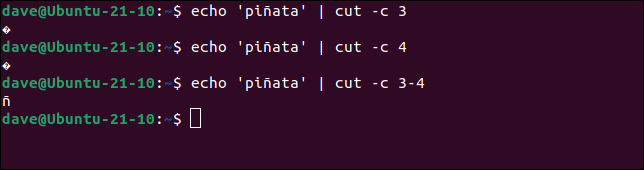
Si solicitamos el carácter 3 o el carácter 4, se nos muestra el símbolo de un carácter no imprimible. Si le pedimos los bytes 3 y 4, el shell los interpreta como “ñ”.
echo 'piñata' | cortar -c 3
echo 'piñata' | cortar -c 4
echo 'piñata' | cortar -c 3-4
Usando corte con datos delimitados
Podemos pedir cutdividir líneas de texto usando un delimitador específico. De forma predeterminada, cut usa un carácter de tabulación, pero es fácil decirle que use lo que queramos. Los campos en el archivo “/etc/passwd” están separados por dos puntos “:”, así que lo usaremos como nuestro delimitador y extraeremos algo de texto.
Las porciones de texto entre los delimitadores se denominan campos y se hace referencia a ellos como bytes o caracteres, pero están precedidos por la -fopción (campos). Puede dejar un espacio entre la «f» y el dígito, o no.
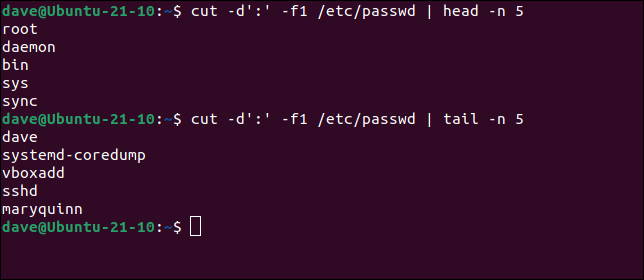
El primer comando usa la -dopción (delimitador) para decirle a cut que use “:” como delimitador. Extraerá el primer campo de cada línea en el archivo “/etc/passwd”. Será una lista larga, por lo que estamos usando headla -nopción (número) para mostrar solo las primeras cinco respuestas. El segundo comando hace lo mismo pero usa tailpara mostrarnos las últimas cinco respuestas.
cortar -d':' -f1 /etc/contraseña | cabeza -n 5
cortar -d':' -f2 /etc/contraseña | cola -n 5
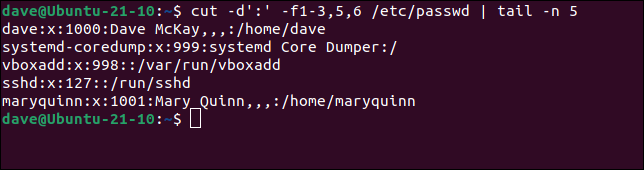
Para extraer una selección de campos, enumérelos como una lista separada por comas. Este comando extraerá los campos uno a tres, cinco y seis.
cortar -d':' -f1-3,5,6 /etc/passwd | cola -n 5
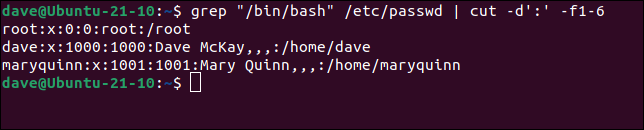
Al incluir grepen el comando, podemos buscar líneas que incluyan “/bin/bash”. Esto significa que podemos enumerar solo aquellas entradas que tienen Bash como shell predeterminado. Por lo general, serán las cuentas de usuario «normales». Le pediremos los campos del uno al seis porque el séptimo campo es el campo de shell predeterminado y ya sabemos qué es, lo estamos buscando.
grep "/bin/bash" /etc/contraseña | cortar -d':' -f1-6
Otra forma de incluir todos los campos excepto uno es usar la --complementopción. Esto invierte la selección de campos y muestra todo lo que no se ha solicitado. Repitamos el último comando pero solo preguntemos por el campo siete. Luego ejecutaremos ese comando nuevamente con la --complementopción.
grep "/bin/bash" /etc/contraseña | cortar -d':' -f7
grep "/bin/bash" /etc/contraseña | cortar -d':' -f7 --complemento
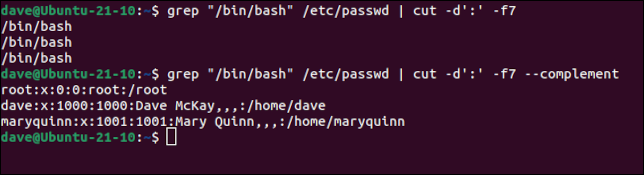
El primer comando encuentra una lista de entradas, pero el campo siete no nos da nada para distinguirlas, por lo que no sabemos a quién se refieren las entradas. En el segundo comando, al agregar la --complementopción obtenemos todo excepto el campo siete.
Tubería cortada En corte
Siguiendo con el archivo “/etc/passwd”, extraigamos el campo cinco. Este es el nombre real del usuario propietario de la cuenta de usuario .
grep "/bin/bash" /etc/contraseña | cortar -d':' -f5
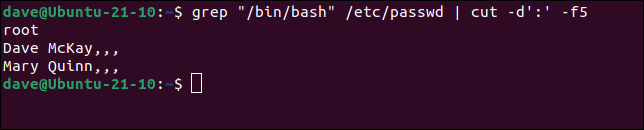
El quinto campo tiene subcampos separados por comas. Rara vez se rellenan, por lo que aparecen como una línea de comas.
Podemos eliminar las comas canalizando la salida del comando anterior a otra invocación de cut. La segunda instancia de cut utiliza la coma “,” como delimitador. La -sopción (solo delimitado) indica cutque se supriman los resultados que no tienen el delimitador en absoluto.
grep "/bin/bash" /etc/contraseña | cortar -d':' -s -f5 | cortar -d',' -s -f1

Debido a que la entrada raíz no tiene subcampos de coma en el quinto campo, se suprime y obtenemos los resultados que buscamos: una lista de los nombres de los usuarios «reales» configurados en esta computadora.
El delimitador de salida
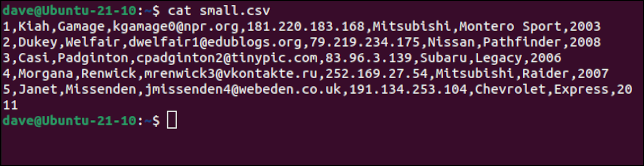
Tenemos un pequeño archivo con algunos valores separados por comas. Los campos en estos datos ficticios son:
- ID : un número de identificación de la base de datos
- First : El primer nombre del sujeto.
- Apellido : El apellido del sujeto.
- email : Su dirección de correo electrónico.
- Dirección IP : Su dirección IP .
- Marca : La marca del vehículo de motor que conducen.
- Modelo : El modelo de vehículo de motor que conducen.
- Año : El año en que se fabricó su vehículo de motor.
gato pequeño.csv
Si le decimos a cut que use la coma como delimitador, podemos extraer campos tal como lo hicimos antes. A veces, tendrá el requisito de extraer datos de un archivo, pero no querrá que se incluya el delimitador de campo en los resultados. Usando el --output-delimiterpodemos decir cortar qué carácter, o de hecho, secuencia de caracteres, usar en lugar del delimitador real.
cortar -d ',' -f 2,3 pequeño.csv
cortar -d ',' -f 2,3 pequeño.csv --output-delimiter=' '
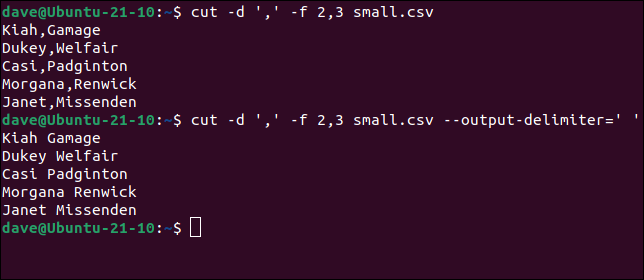
El segundo comando le dice cutque reemplace las comas con espacios.
Podemos llevar esto más lejos y usar esta función para convertir la salida en una lista vertical. Este comando utiliza un carácter de nueva línea como delimitador de salida. Tenga en cuenta el «$» que debemos incluir para que se actúe sobre el carácter de nueva línea y no se interprete como una secuencia literal de dos caracteres.
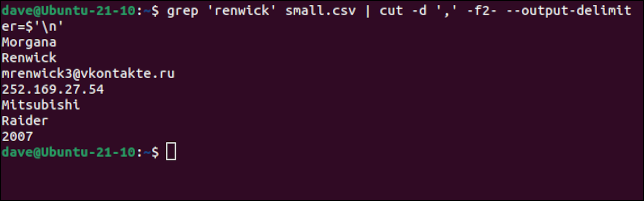
Usaremos greppara filtrar la entrada de Morgana Renwick y pediremos cutimprimir todos los campos desde el campo dos hasta el final del registro, y usar un carácter de nueva línea como delimitador de salida.
grep 'renwick' pequeño.csv | cortar -d ',' -f2- --output-delimiter=$''
Un Oldie pero Goldie
Al momento de escribir este artículo, el comando Little Cut se acerca a su 40 cumpleaños, y todavía lo estamos usando y escribiendo sobre él hoy. Supongo que cortar texto hoy es lo mismo que hace 40 años. Es decir, mucho más fácil cuando tienes la herramienta adecuada a mano.

