Tabla de contenidos
El curlcomando de Linux puede hacer mucho más que descargar archivos. Descubra de qué curles capaz y cuándo debe usarlo en lugar de wget.
curl vs. wget: ¿Cuál es la diferencia?
Las personas a menudo tienen dificultades para identificar las fortalezas relativas de los comandos wgety curl. Los comandos tienen cierta superposición funcional. Cada uno puede recuperar archivos de ubicaciones remotas, pero ahí es donde termina la similitud.
wgetes una herramienta fantástica para descargar contenido y archivos . Puede descargar archivos, páginas web y directorios. Contiene rutinas inteligentes para recorrer enlaces en páginas web y descargar contenido de forma recursiva en todo un sitio web. Es insuperable como administrador de descargas de línea de comandos.
curlsatisface una necesidad completamente diferente . Sí, puede recuperar archivos, pero no puede navegar de forma recursiva en un sitio web en busca de contenido para recuperar. Lo que curlrealmente hace es permitirle interactuar con sistemas remotos al realizar solicitudes a esos sistemas y recuperar y mostrar sus respuestas. Esas respuestas pueden ser archivos y contenido de la página web, pero también pueden contener datos proporcionados a través de un servicio web o API como resultado de la «pregunta» formulada por la solicitud curl.
Y curlno se limita a sitios web. curladmite más de 20 protocolos, incluidos HTTP, HTTPS, SCP, SFTP y FTP. Y posiblemente, debido a su manejo superior de las tuberías de Linux, se curlpuede integrar más fácilmente con otros comandos y scripts.
El autor de curltiene una página web que describe las diferencias que ve entre curly wget.
Instalación de curl
De las computadoras utilizadas para investigar este artículo, Fedora 31 y Manjaro 18.1.0 curl ya se habían instalado. curltenía que estar instalado en Ubuntu 18.04 LTS. En Ubuntu, ejecute este comando para instalarlo:
sudo apt-get install curl

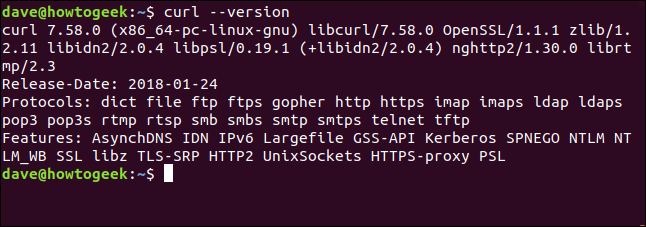
La versión curl
La --versionopción hace curlreportar su versión. También enumera todos los protocolos que admite.
curl --version
Recuperar una página web
Si apuntamos curla una página web, la recuperará.
rizo https://www.bbc.com

Pero su acción predeterminada es descargarlo en la ventana del terminal como código fuente.
Cuidado : si no le dice curlque quiere algo almacenado como un archivo, siempre lo volcará a la ventana del terminal. Si el archivo que está recuperando es un archivo binario, el resultado puede ser impredecible. El shell puede intentar interpretar algunos de los valores de bytes en el archivo binario como caracteres de control o secuencias de escape.
Guardar datos en un archivo
Digamos a curl que redirija la salida a un archivo:
curl https://www.bbc.com> bbc.html
Esta vez no vemos la información recuperada, se envía directamente al archivo por nosotros. Debido a que no hay salida de ventana de terminal para mostrar, curlgenera un conjunto de información de progreso.
No hizo esto en el ejemplo anterior porque la información de progreso se habría dispersado por todo el código fuente de la página web, por lo que curlla suprimió automáticamente.
En este ejemplo, curldetecta que la salida se redirige a un archivo y que es seguro generar la información de progreso.
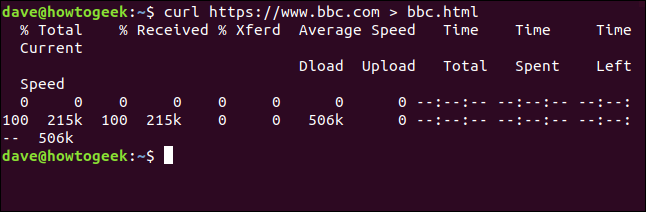
La información proporcionada es:
- % Total : la cantidad total a recuperar.
- % Recibido : el porcentaje y los valores reales de los datos recuperados hasta el momento.
- % Xferd : el porcentaje y el envío real, si se están cargando datos.
- Velocidad media Dload : La velocidad promedio de descarga.
- Carga de velocidad promedio : la velocidad de carga promedio.
- Tiempo total : la duración total estimada de la transferencia.
- Tiempo invertido : el tiempo transcurrido hasta ahora para esta transferencia.
- Tiempo restante: el tiempo estimado que queda para que se complete la transferencia.
- Velocidad actual : la velocidad de transferencia actual para esta transferencia.
Debido a que redirigimos la salida de curl un archivo, ahora tenemos un archivo llamado «bbc.html».
Al hacer doble clic en ese archivo, se abrirá su navegador predeterminado para que muestre la página web recuperada.
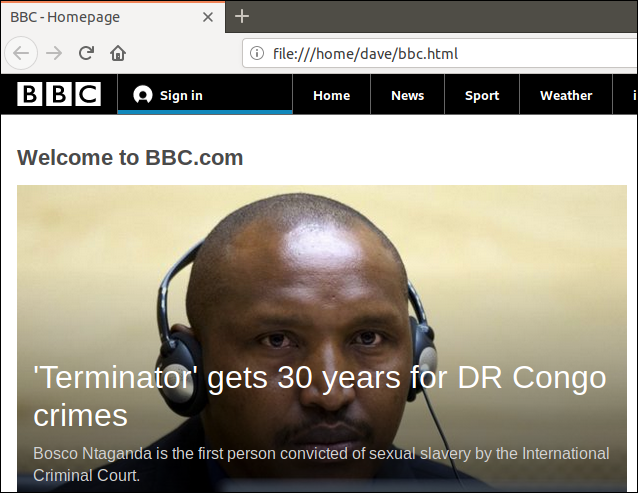
Tenga en cuenta que la dirección en la barra de direcciones del navegador es un archivo local en esta computadora, no un sitio web remoto.
No tenemos que redirigir la salida para crear un archivo. Podemos crear un archivo usando la -oopción (salida) y diciendo curlque creemos el archivo. Aquí usamos la -oopción y proporcionamos el nombre del archivo que deseamos crear «bbc.html».
curl -o bbc.html https://www.bbc.com
Uso de una barra de progreso para monitorear descargas
Para reemplazar la información de descarga basada en texto por una barra de progreso simple, use la -#opción (barra de progreso).
curl -x -o bbc.html https://www.bbc.com
Reinicio de una descarga interrumpida
Es fácil reiniciar una descarga que se ha terminado o interrumpido. Comencemos la descarga de un archivo considerable. Usaremos la última compilación de soporte a largo plazo de Ubuntu 18.04. Estamos usando la --outputopción para especificar el nombre del archivo en el que deseamos guardarlo: «ubuntu180403.iso».
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

La descarga comienza y avanza hacia su finalización.
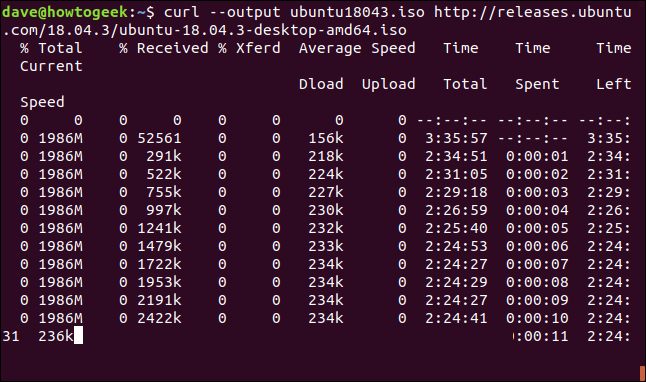
Si interrumpimos a la fuerza la descarga con Ctrl+C, regresamos al símbolo del sistema y la descarga se abandona.
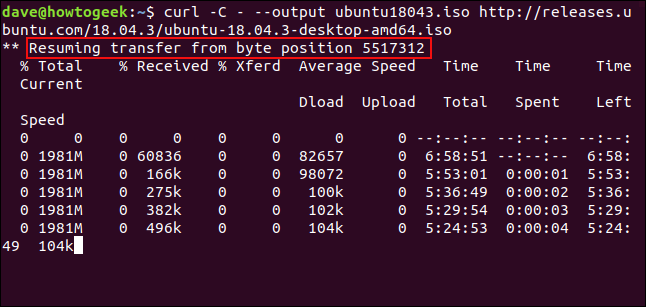
Para reiniciar la descarga, use la -Copción (continuar en). Esto hace curlque se reinicie la descarga en un punto o desplazamiento especificado dentro del archivo de destino. Si utiliza un guión -como desplazamiento, curlobservará la parte del archivo ya descargada y determinará el desplazamiento correcto que se utilizará por sí mismo.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Se reinicia la descarga. curlinforma el desplazamiento en el que se está reiniciando.
Recuperando encabezados HTTP
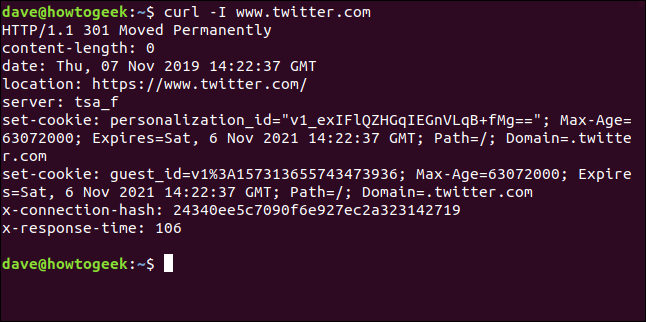
Con la -Iopción (head), puede recuperar solo los encabezados HTTP. Esto es lo mismo que enviar el comando HTTP HEAD a un servidor web.
curl -I www.twitter.com

Este comando solo recupera información; no descarga páginas web ni archivos.
Descarga de varias URL
Usando xargspodemos descargar múltiples URL a la vez. Quizás queramos descargar una serie de páginas web que componen un solo artículo o tutorial.
Copie estas URL en un editor y guárdelas en un archivo llamado «urls-to-download.txt». Podemos usar xargspara tratar el contenido de cada línea del archivo de texto como un parámetro al que alimentará curl, a su vez.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
Este es el comando que debemos usar para xargspasar estas URL de curluna en una:
xargs -n 1 curl -O <urls-to-download.txt
Tenga en cuenta que este comando usa el -Ocomando de salida (archivo remoto), que usa una «O» mayúscula. Esta opción hace curlque se guarde el archivo recuperado con el mismo nombre que tiene el archivo en el servidor remoto.
La -n 1opción le dice xargsque trate cada línea del archivo de texto como un solo parámetro.
Cuando ejecute el comando, verá que varias descargas comienzan y terminan, una tras otra.
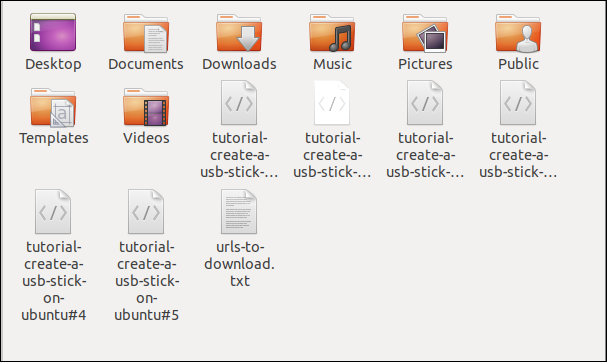
Verificar en el explorador de archivos muestra que se han descargado varios archivos. Cada uno lleva el nombre que tenía en el servidor remoto.
Descarga de archivos desde un servidor FTP
Usar curlcon un servidor de Protocolo de transferencia de archivos (FTP) es fácil, incluso si tiene que autenticarse con un nombre de usuario y contraseña. Para pasar un nombre de usuario y contraseña, curluse la -uopción (usuario) y escriba el nombre de usuario, dos puntos “:” y la contraseña. No ponga un espacio antes o después del colon.
Este es un servidor FTP gratuito para pruebas alojado por Rebex . El sitio FTP de prueba tiene un nombre de usuario preestablecido de «demostración» y la contraseña es «contraseña». No utilice este tipo de nombre de usuario y contraseña débiles en un servidor FTP de producción o «real».
curl -u demo: contraseña ftp://test.rebex.net
curl se da cuenta de que lo estamos apuntando a un servidor FTP y devuelve una lista de los archivos que están presentes en el servidor.

El único archivo en este servidor es un archivo «readme.txt», de 403 bytes de longitud. Vamos a recuperarlo. Utilice el mismo comando que hace un momento, con el nombre de archivo adjunto:
curl -u demo: contraseña ftp://test.rebex.net/readme.txt

El archivo se recupera y curlmuestra su contenido en la ventana del terminal.
En casi todos los casos, será más conveniente guardar el archivo recuperado en el disco, en lugar de mostrarlo en la ventana de la terminal. Una vez más podemos usar el -Ocomando de salida (archivo remoto) para guardar el archivo en el disco, con el mismo nombre de archivo que tiene en el servidor remoto.
curl -O -u demo: contraseña ftp://test.rebex.net/readme.txt

El archivo se recupera y se guarda en el disco. Podemos utilizar lspara comprobar los detalles del archivo. Tiene el mismo nombre que el archivo en el servidor FTP y tiene la misma longitud, 403 bytes.
ls -hl readme.txt
Envío de parámetros a servidores remotos
Algunos servidores remotos aceptarán parámetros en las solicitudes que se les envíen. Los parámetros pueden usarse para formatear los datos devueltos, por ejemplo, o pueden usarse para seleccionar los datos exactos que el usuario desea recuperar. A menudo es posible interactuar con interfaces de programación de aplicaciones web (API) utilizando curl.
Como ejemplo simple, el sitio web de ipify tiene una API que se puede consultar para determinar su dirección IP externa.
curl https://api.ipify.org
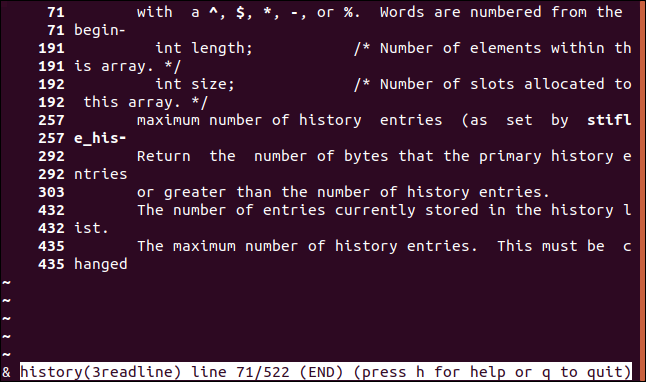
Añadiendo el format parámetro al comando, con el valor de “json” podremos volver a solicitar nuestra dirección IP externa, pero esta vez los datos devueltos estarán codificados en formato JSON .
curl https://api.ipify.org?format=json
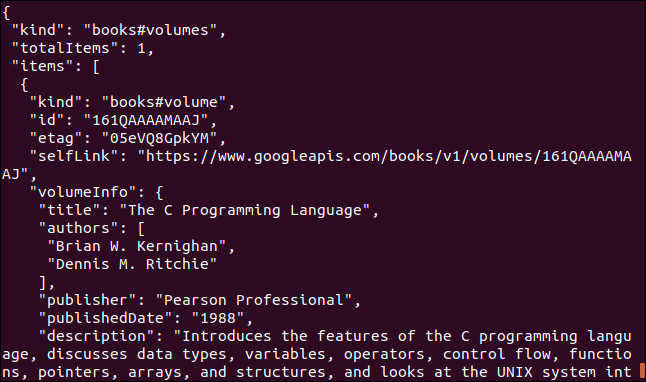
Aquí hay otro ejemplo que utiliza una API de Google. Devuelve un objeto JSON que describe un libro. El parámetro que debe proporcionar es el número de libro estándar internacional (ISBN) de un libro. Puede encontrarlos en la contraportada de la mayoría de los libros, generalmente debajo de un código de barras. El parámetro que usaremos aquí es «0131103628».
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628

Los datos devueltos son completos:
A veces rizo, a veces wget
Si quisiera descargar contenido de un sitio web y hacer que la estructura de árbol del sitio web buscara de forma recursiva ese contenido, usaría wget.
Si quisiera interactuar con un servidor remoto o API, y posiblemente descargar algunos archivos o páginas web, usaría curl. Especialmente si el protocolo era uno de los muchos no admitidos por wget.